Kubernetes 网络模型
{Back to Index}
Table of Contents
1 K8S 组网规范 1
Kubernetes 对所有网络设施的实施,需要满足以下的基本要求:
- 节点上的 Pod 可以不通过 NAT 和其他任何节点上的 Pod 通信
- 节点上的任何进程可以和节点上的所有Pod通信
- 那些运行在节点的主机网络里的 Pod 可以不通过 NAT 和所有节点上的 Pod 通信 (Pod 自身的 IP 和其他 Pod 看到它的 IP 是一致的)
2 容器之间的通信
Pod 本质上是一组共享 Network Namespace 的容器,因此这些容器使用相同的 IP 地址和端口分配空间。
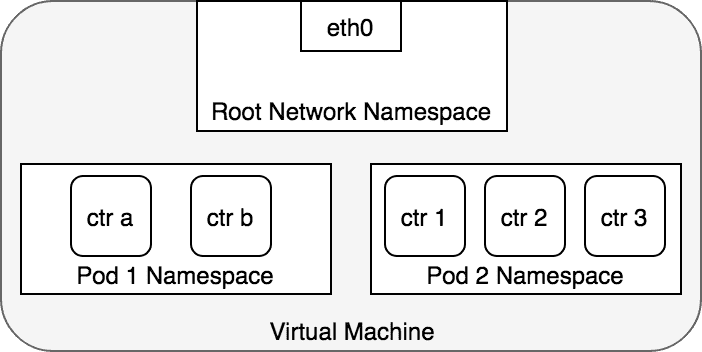
Figure 1: 每个 Pod 使用单独的命名空间
3 Pod 之间的通信
在同一个主机上,Pod 之间的通信本质上是不同命名空间之间的通信,使用 Linux Virtual Ethernet Device 可以将不同的命名空间联结起来。
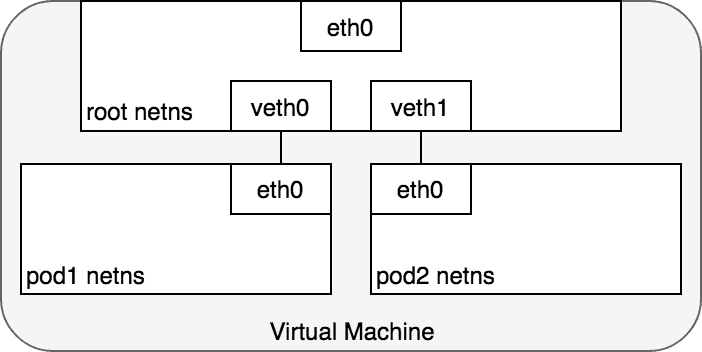
Figure 2: veth pair 将主机上的 Pod 与根命名空间联结起来
3.1 Linux Ethernet bridge
为了透过根命名空间使得 Pod 之间可以通信,需要使用 Linux Ethernet bridge ,它是虚拟二层网络设备,用于连接多个网段。
当网桥接收到一个数据帧,会广播 ARP 消息至所有与之相连接的设备,响应 ARP 消息的设备 MAC 会被记录于关联表中, 即网桥利用 ARP 协议将 MAC 与 IP 关联起来,后续相同 IP 的数据将根据关联表转发至对应的冲突域。
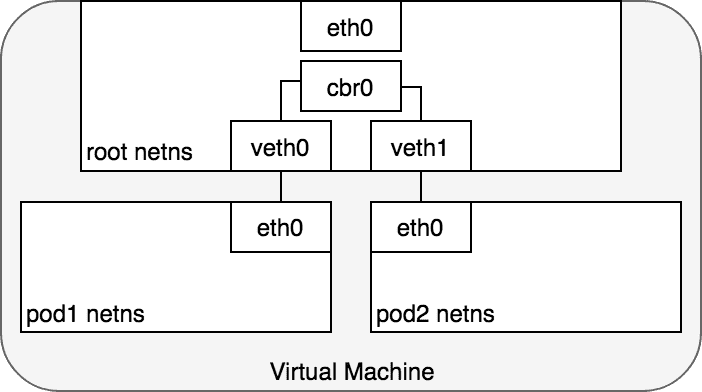
Figure 3: 通过网桥连接不同的命名空间
3.2 数据包的传递(单机)
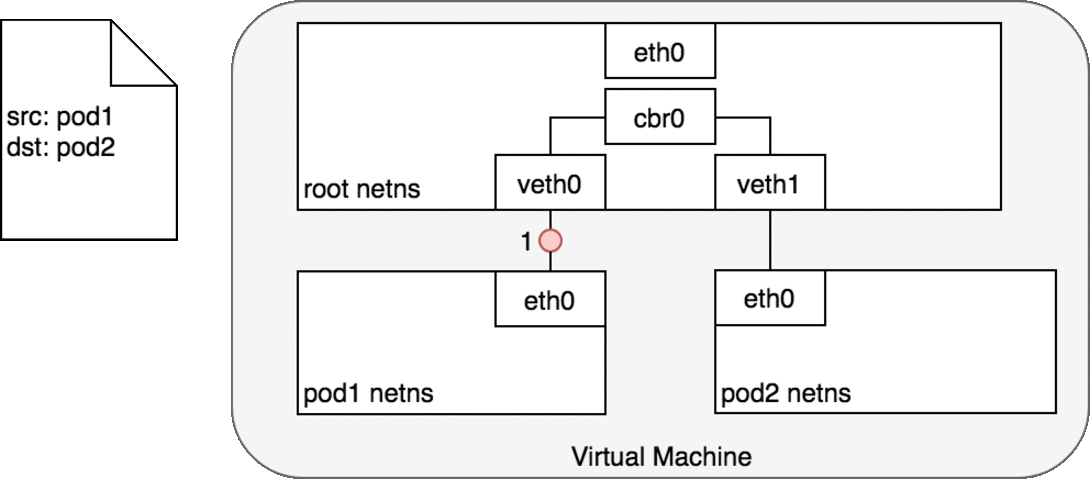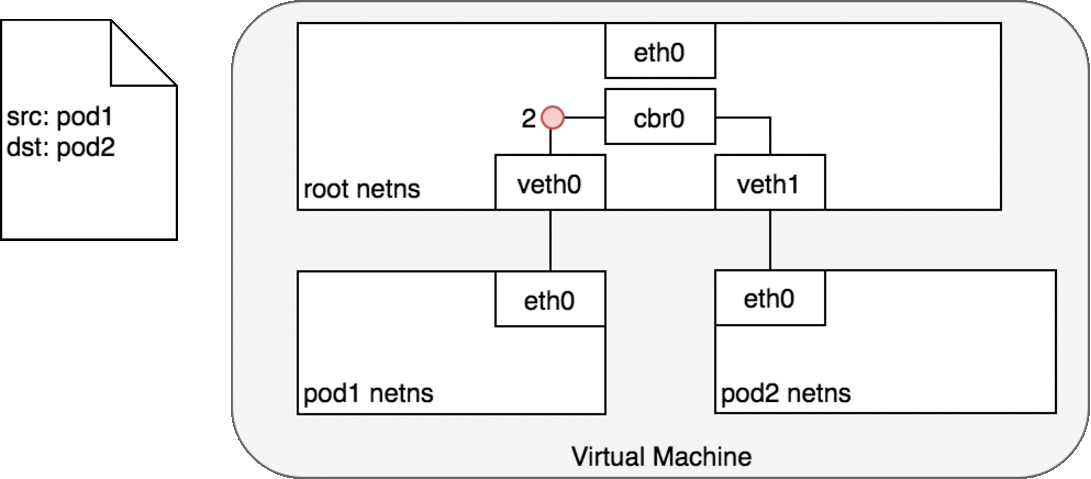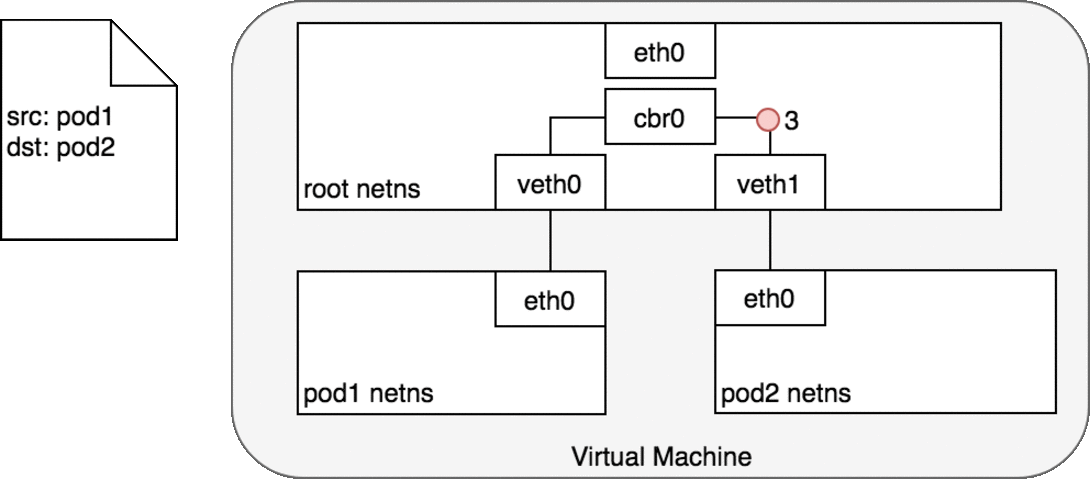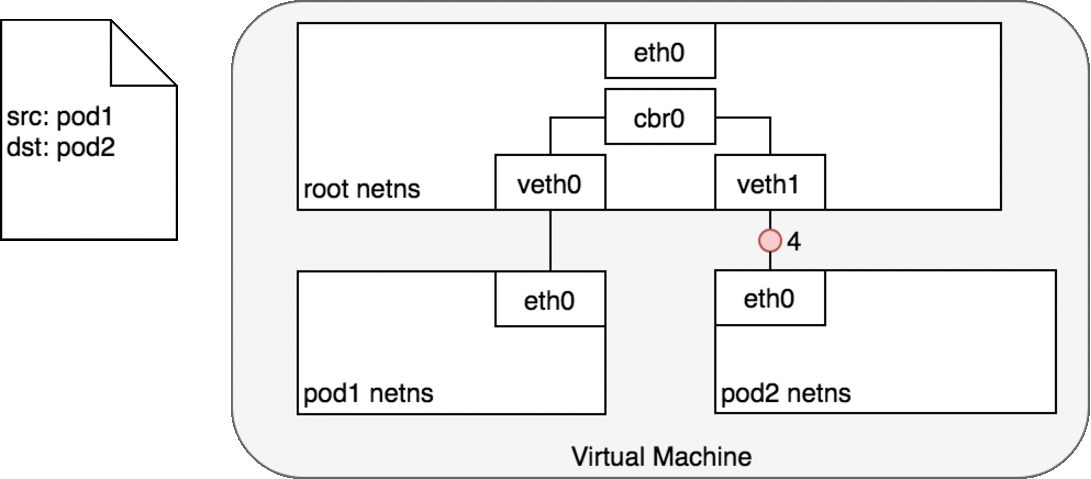
Figure 4: 数据包在同一主机内的 Pod 之间传递
Pod 1 将数据包发送至 eth0 ,该 eth0 和 veth0 是一对 veth , veth0 也会收到数据包 (1)。
网桥 cbr0 将 veth0 和 veth1 联结在一起,当数据包到达网桥后,通过 ARP 协议,被转发到 veth1 (3)。
veth1 上的数据包直接转发至 Pod 2 命名空间中的 eth0 (4)。
3.3 数据包的传递(跨主机)
通常,集群中的每个主机会被分配一个 CIDR block 用于指定该主机上 Pod 可以使用的 IP 地址范围。
当目标是某个 CIDR block 地址的数据包到达主机,该主机会将其转发至正确的主机(通过隧道技术),并进而转发至正确的 Pod 。
下图示意了数据包在不同主机间的传递(假设网络可以将属于某个 CIDR block 的数据转发至正确的主机)。
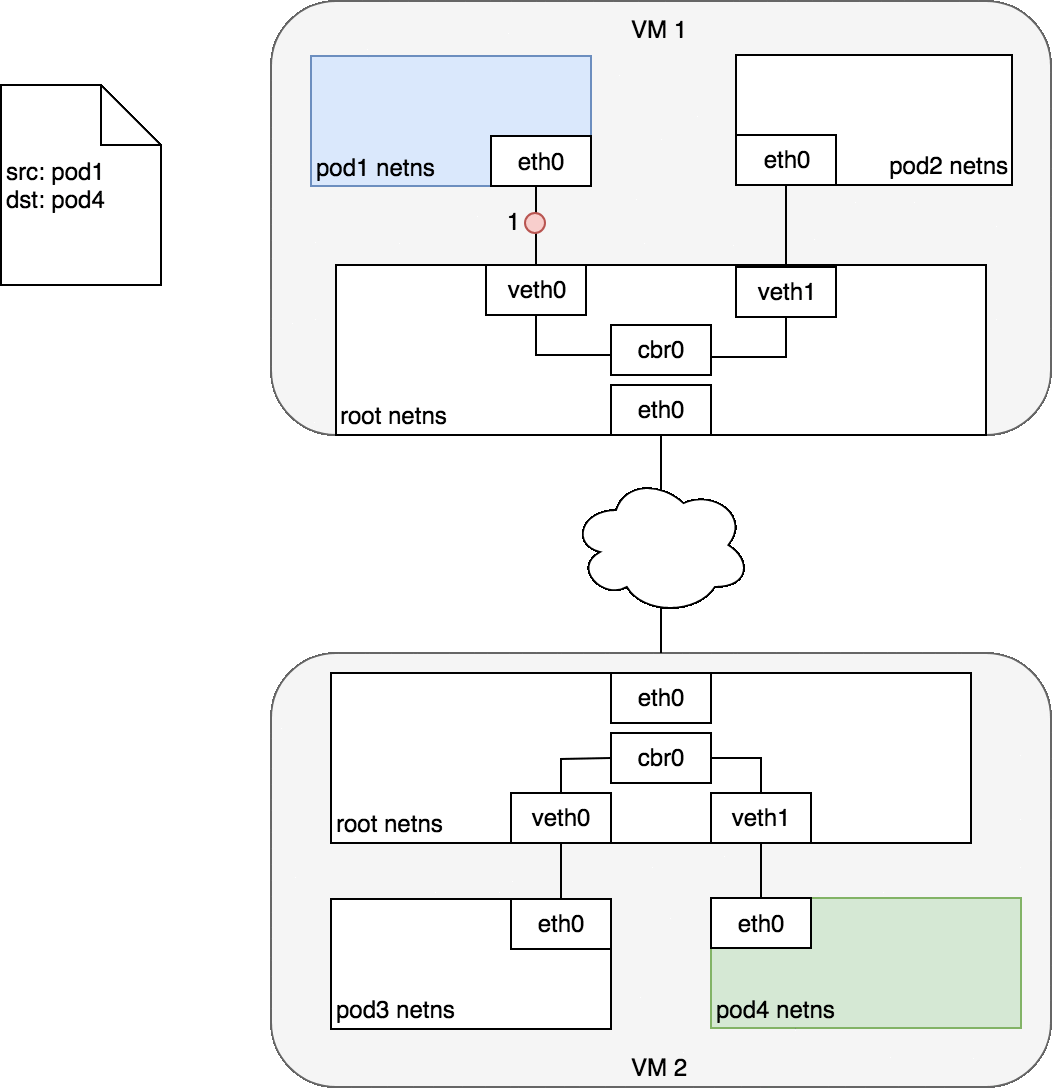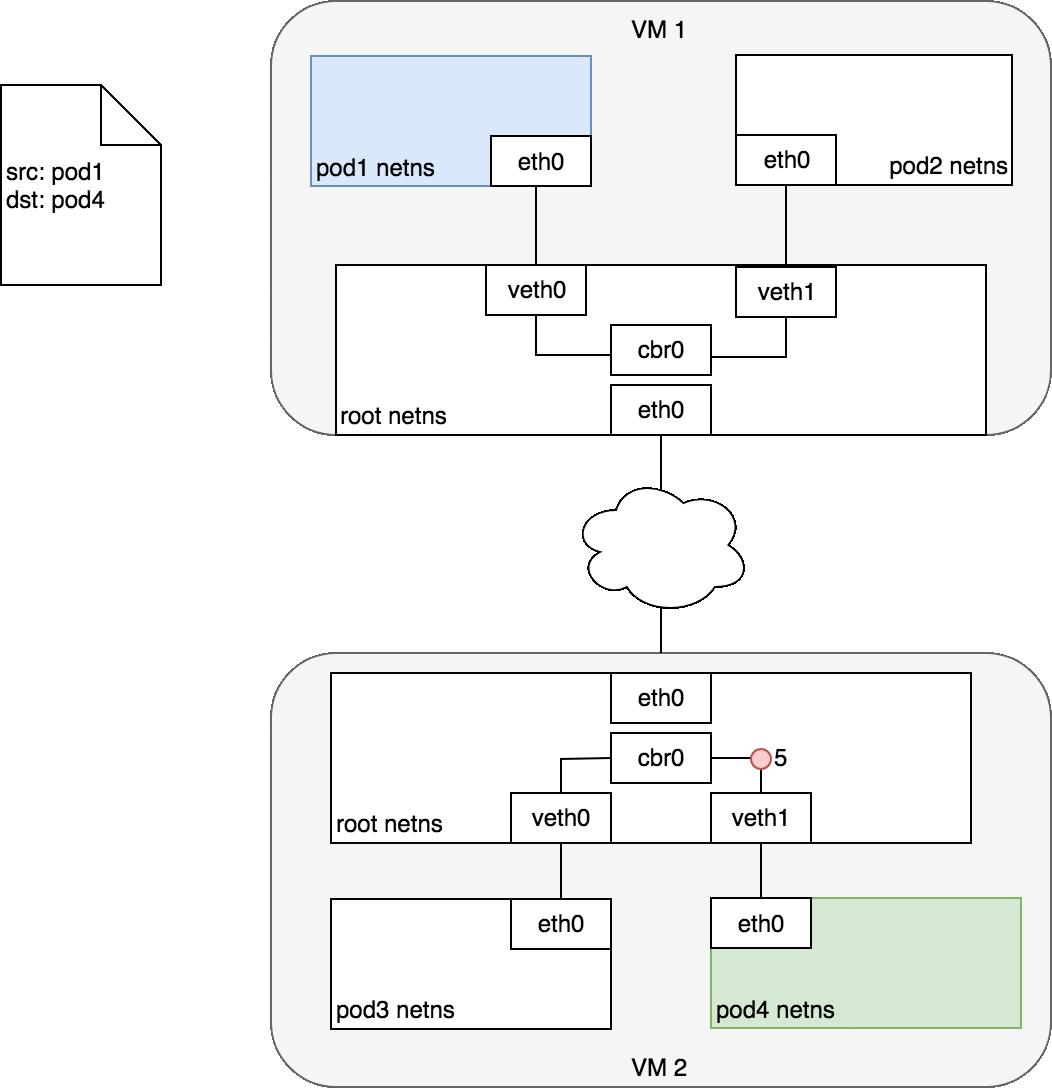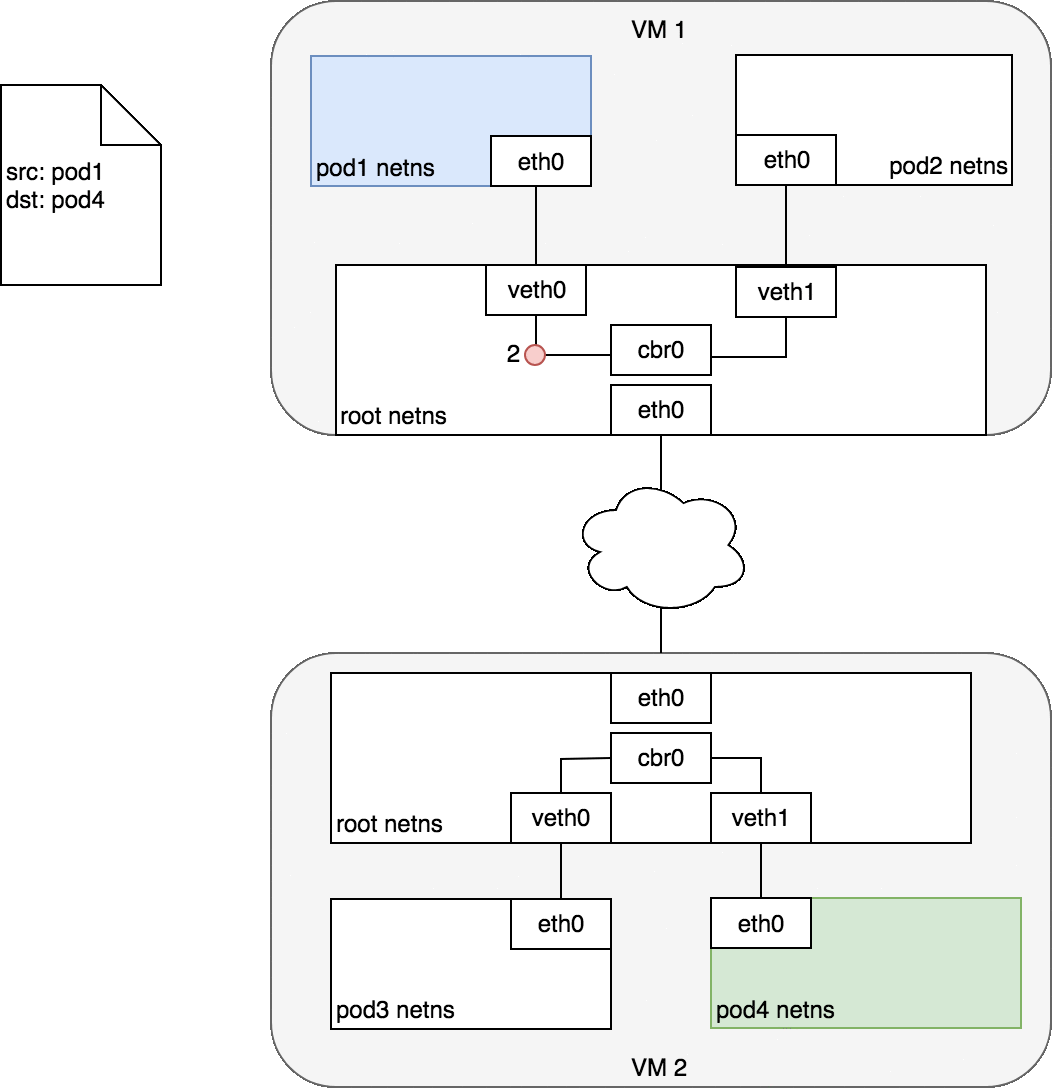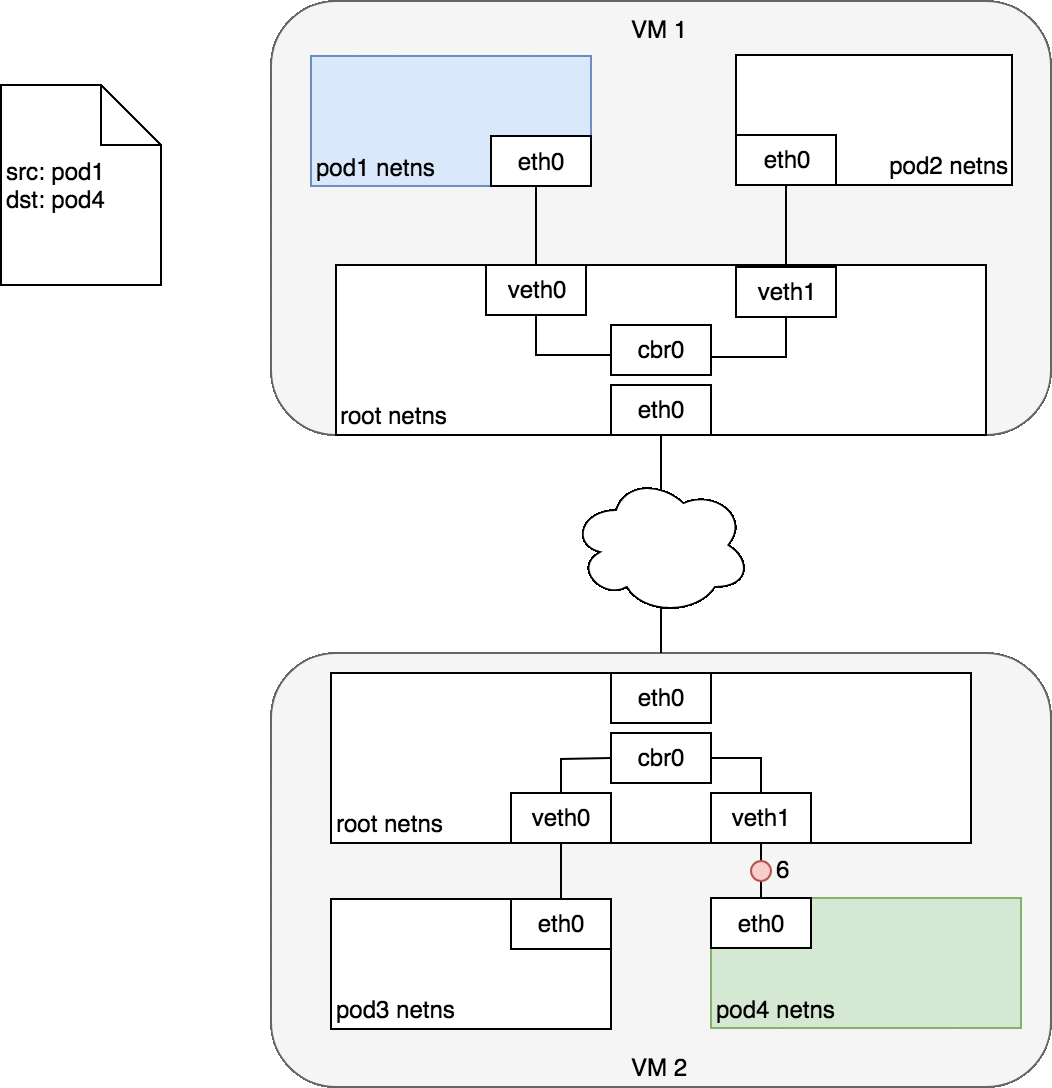
Figure 5: 数据包在跨主机的 Pod 之间传递
Pod 1 中的数据会到达根命名空间中的网桥 cbr0 (2) ,此时,网桥上的 ARP 过程会失败,因为连在其上的设备没有一个可以响应。
接着数据会通过隧道技术的封装而进入网络 (3) ,并发送至正确的主机上 (4) ,出现在 VM 2 的根命名空间中 (eth0) 。
通过网桥,数据被路由至正确的虚拟设备 veth1 (5) 。最终,到达 eth0 (6) 。
4 Pod 与 Service 的通信
当创建 Service 时,cluster IP 也会被创建出来,在集群内部,流向 Cluster IP 的数据会以 Round Robin 的方式导向该 Service 的支撑 Pods , 即 K8S 内部利用这种机制实现了负载均衡的功能。
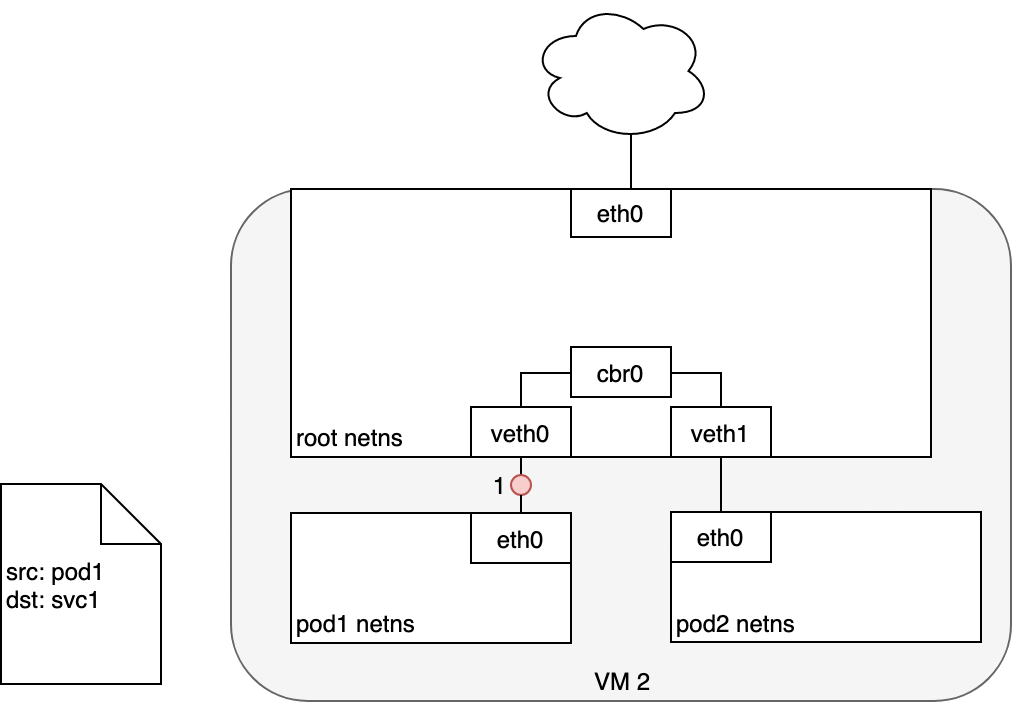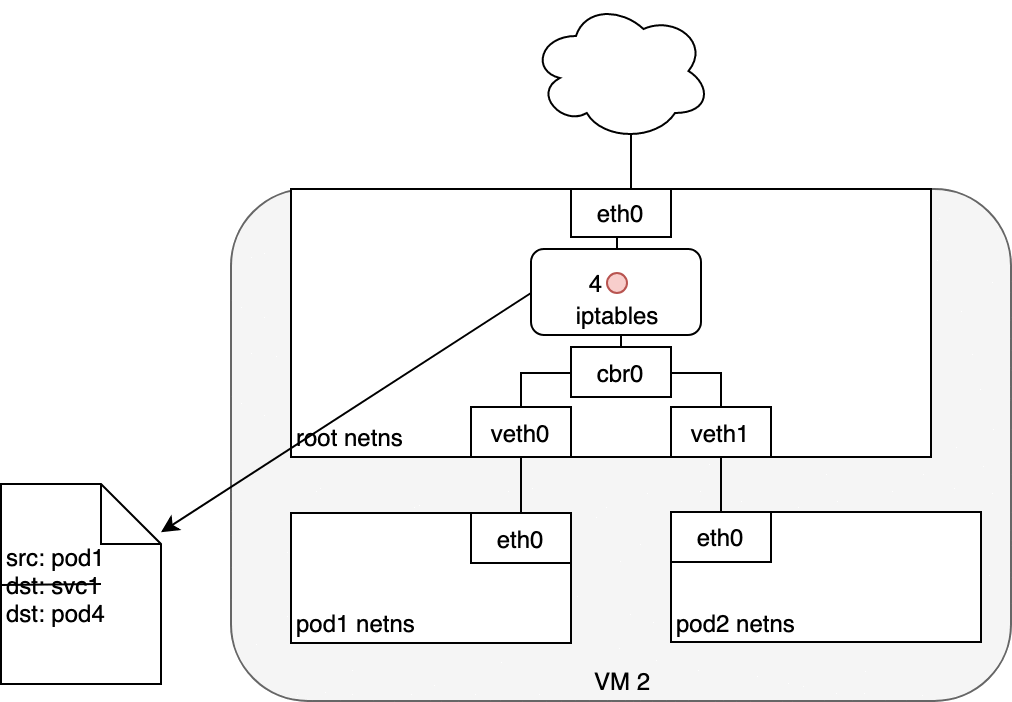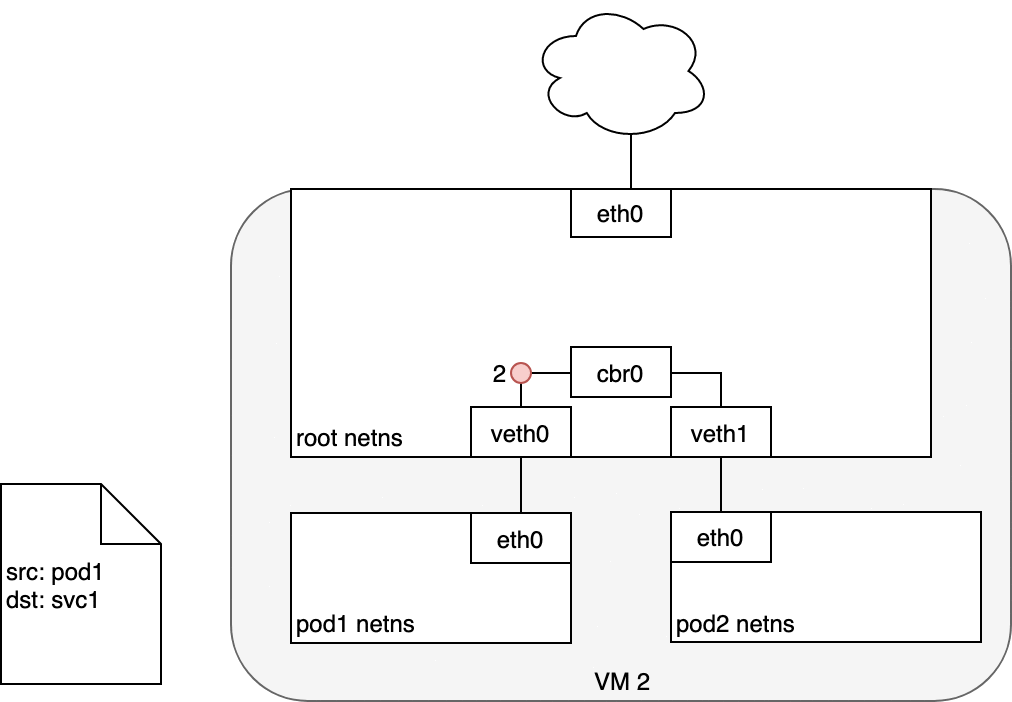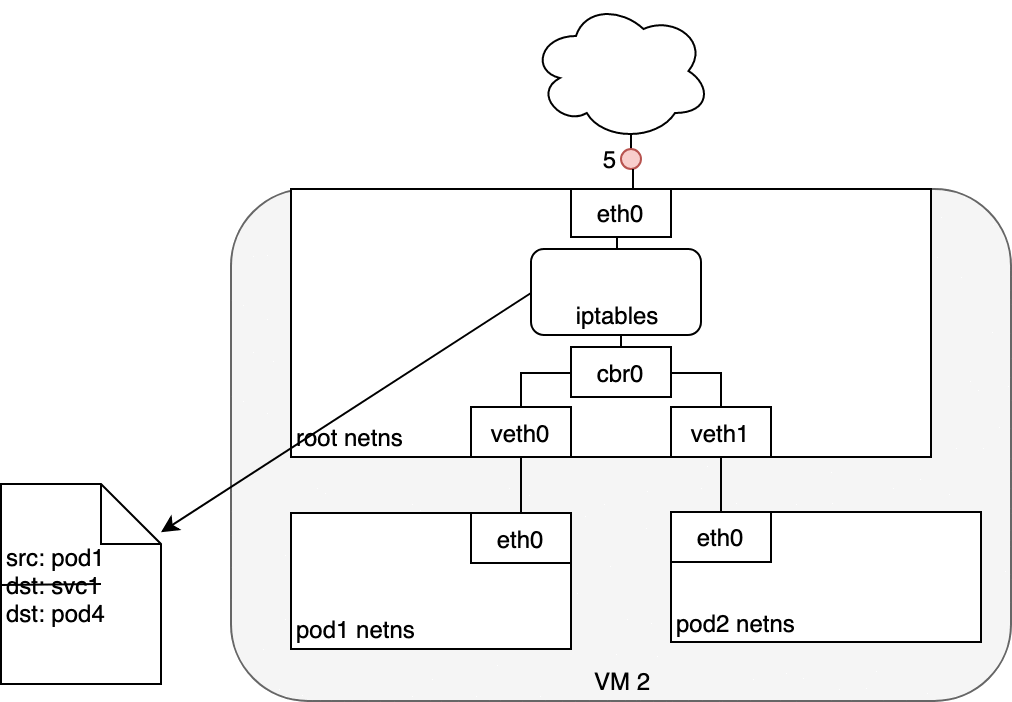
Figure 6: 数据从 Pod 发送至 Service
网桥会选择将数据包通过默认路由 eth0 发送出去 (3) 。
在 eth0 接收数据之前,IPTABLES 会对数据包进行处理,它会根据规则(这些规则是由 kube-proxy 负责维护的)
将数据包的目标 IP 从 service IP 改为具体某个 Pod 的 IP (4) 。
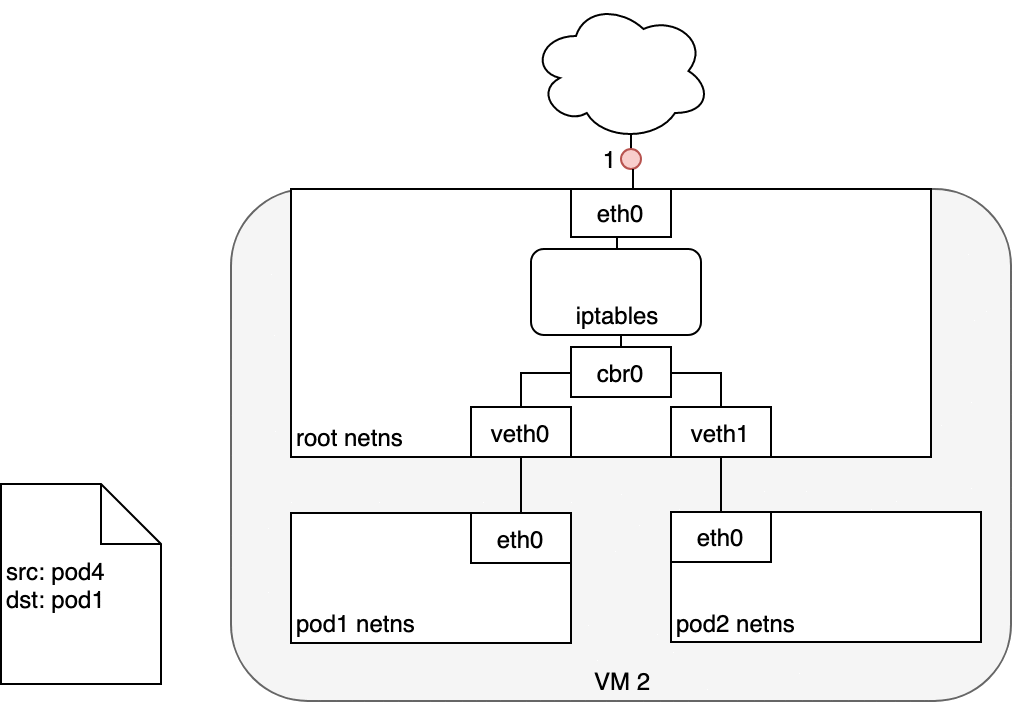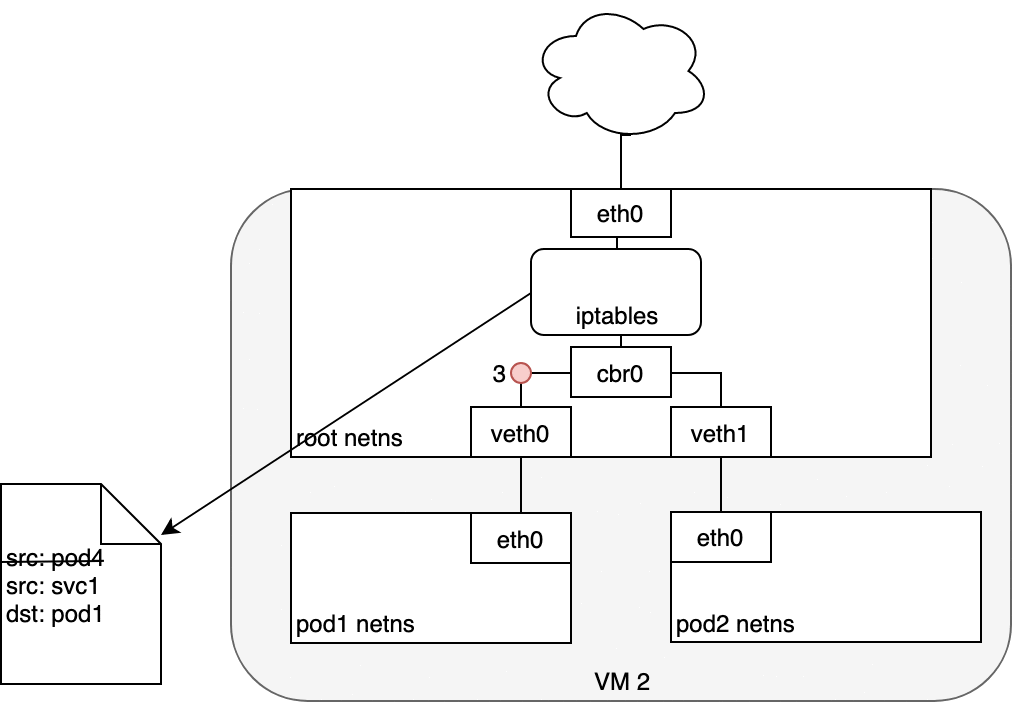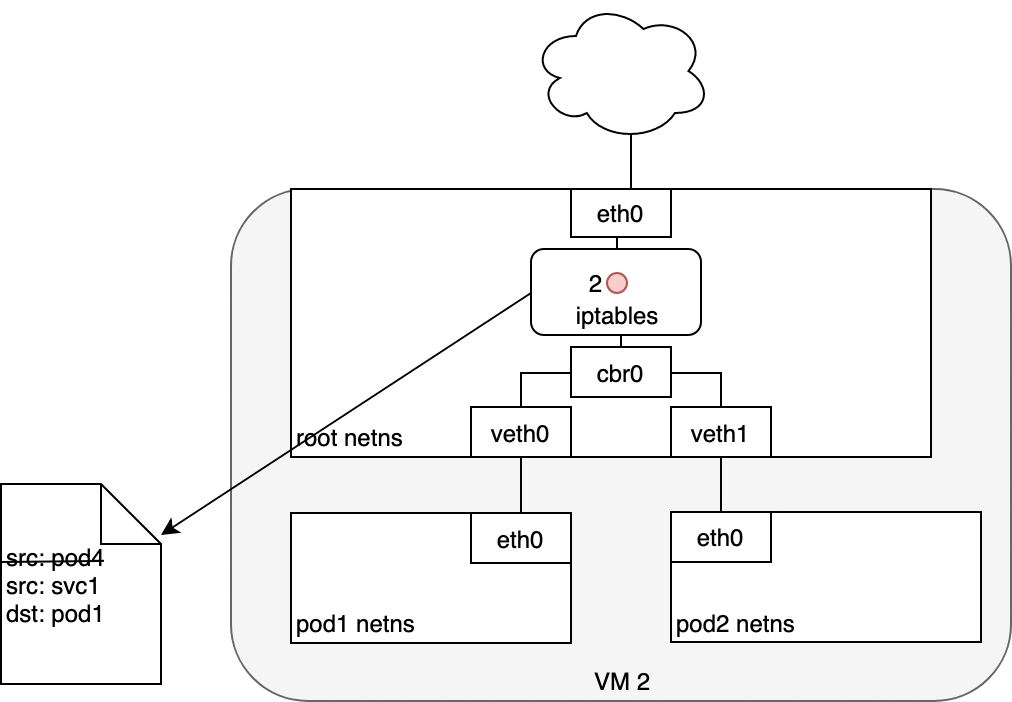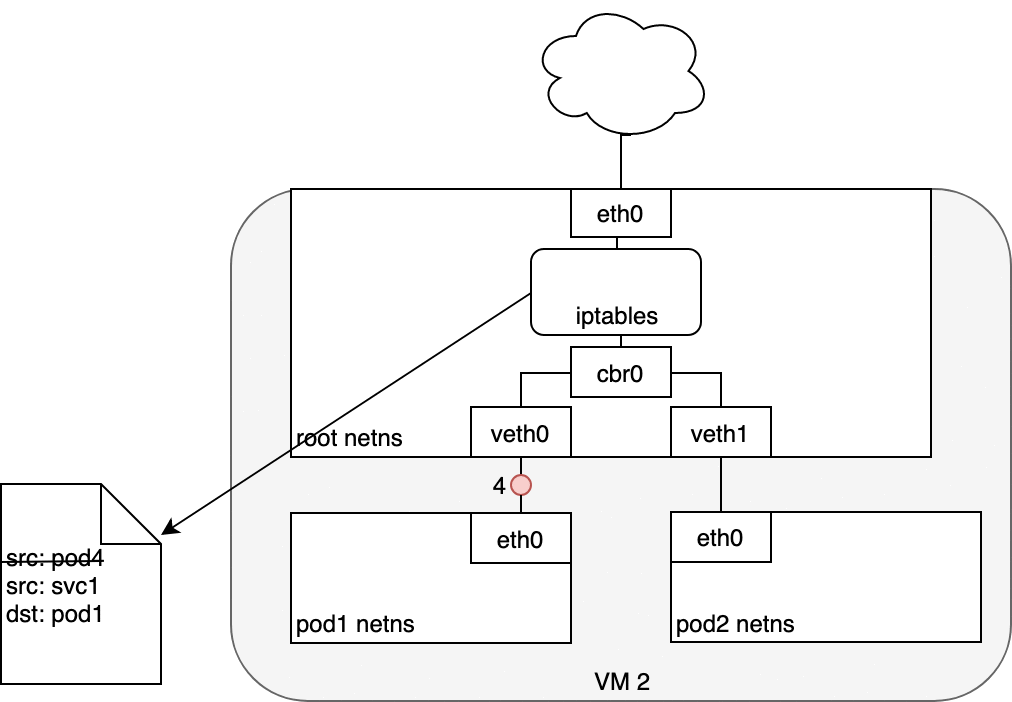
Figure 7: 数据从 Service 发送至 Pod
Service Pod 返回的数据包的源 IP 为它自己的地址,目标 IP 为发送方 Pod 的 IP 地址 (1) 。
当数据到达目标主机,借助于 conntrack 模块,IPTABLES 将源地址再改回 Service 的 cluster IP (2) 。
5 与 Internet 的通信
5.1 Pod 访问 Internet
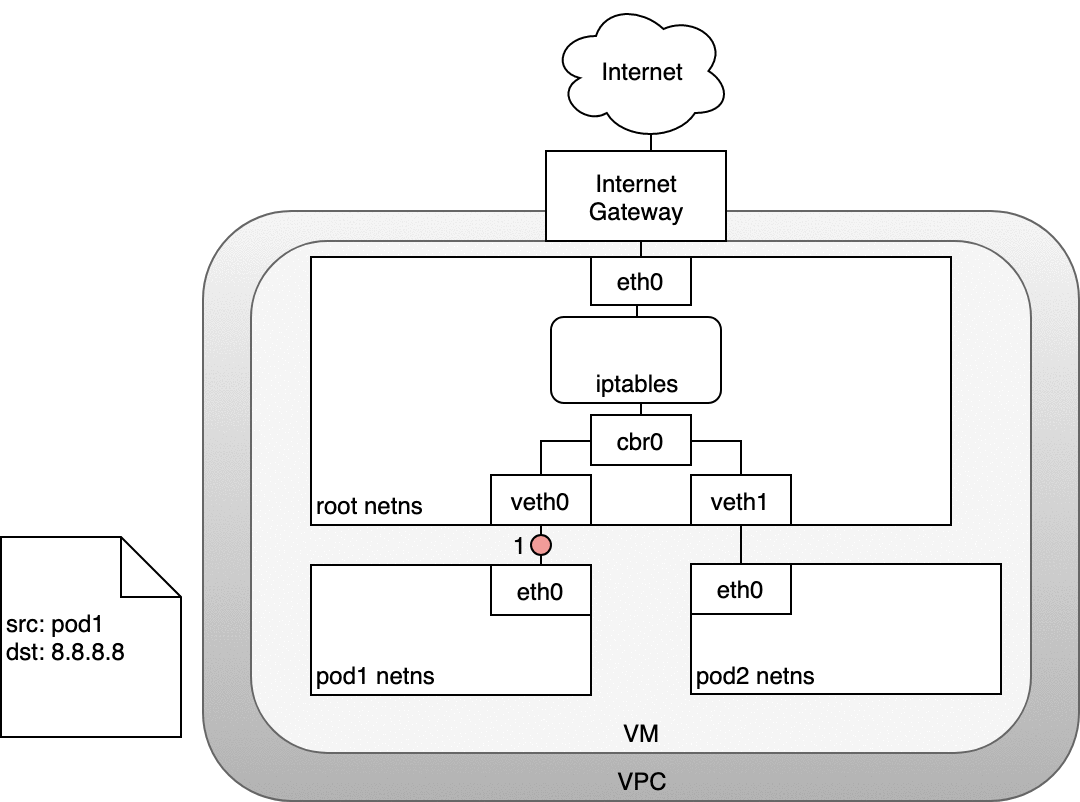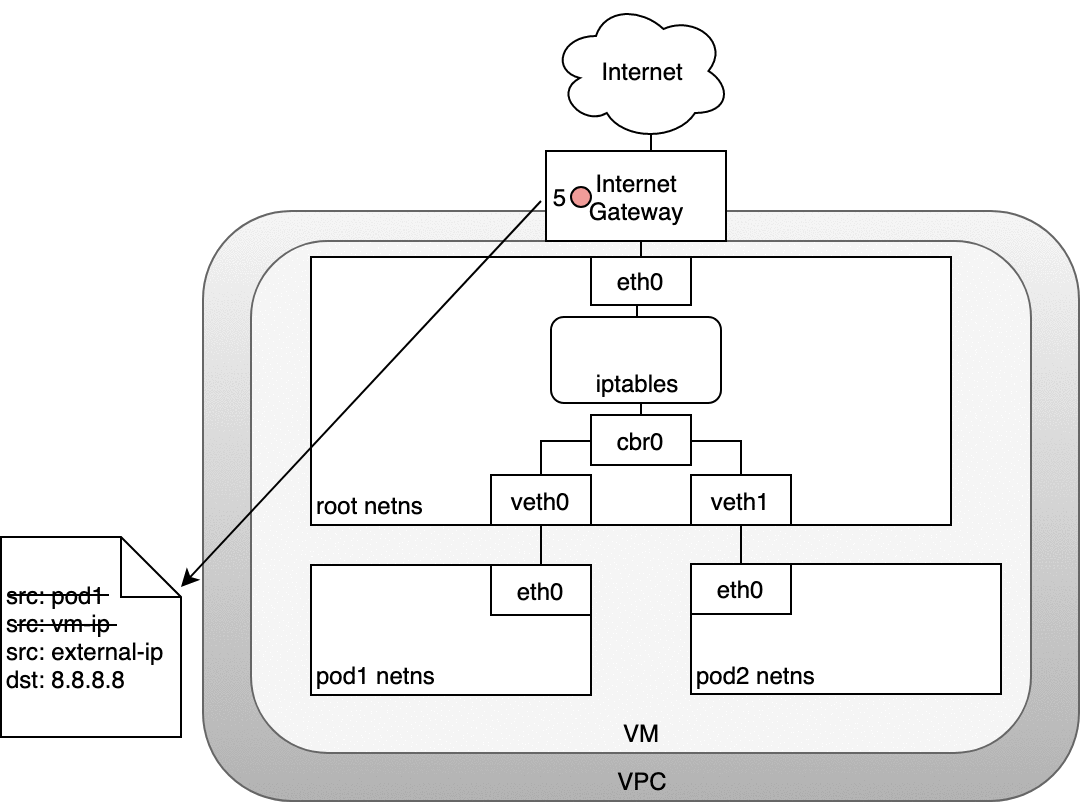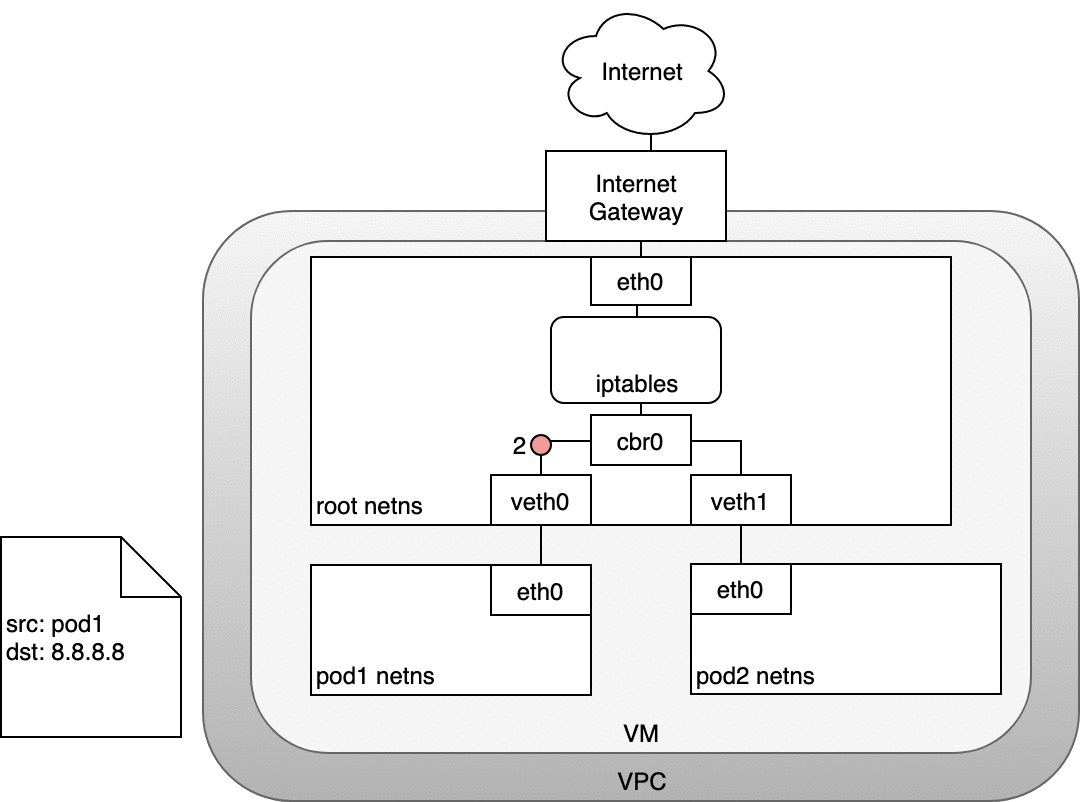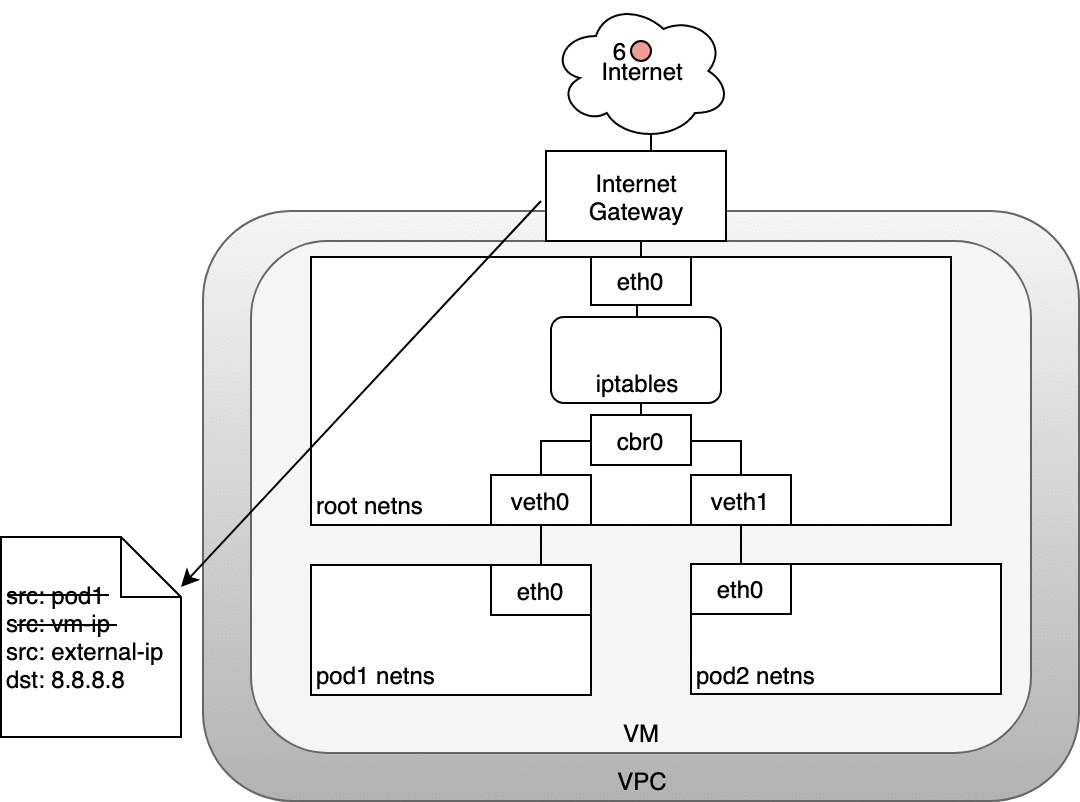
Figure 8: 数据包从 Pod 路由到 Internet
在数据包到达 eth0 前,IPTABLES 会先对其进行处理。假设数据包的源地址仍然为 Pod 的 IP ,该数据包会被 Internet 网关拒绝,因为网关 NAT 只接受 VM 的 IP 。
因此,IPTABLES 必须使用 SNAT ,即将源地址修改为 VM 的内网 IP ,这样,数据包就能离开 VM (4) 从而到达网关 (5) 。
接着,网关会再做一次 NAT :将源地址从 VM 的内部 IP 改为外部 IP ,最终数据包进入公网 (6) 。
返回的数据包则会依次执行相反的操作:将源地址修改回每一层可以理解的 IP ,即内网 IP ( VM 层),Pod IP ( Pod 命名空间层)。
5.2 Internet 访问 Service
从外网访问集群内部的 Service 通常有两种解决方案:
- 使用 LoadBalancer
- 使用 Ingress controller
5.2.1 LoadBalancer (L4)
创建 Service 时,可以指定一个 LoadBalancer ,LoadBalancer 一般由 云服务商 实现。Service 会将 IP 地址通知给 LoadBalancer 。
LoadBalancer 知道其背后所有 VM 的地址,并会将流量均匀的分布在这些主机上。当流量到达主机后,IPTABLES 再负责转发到正确的 Pod 。
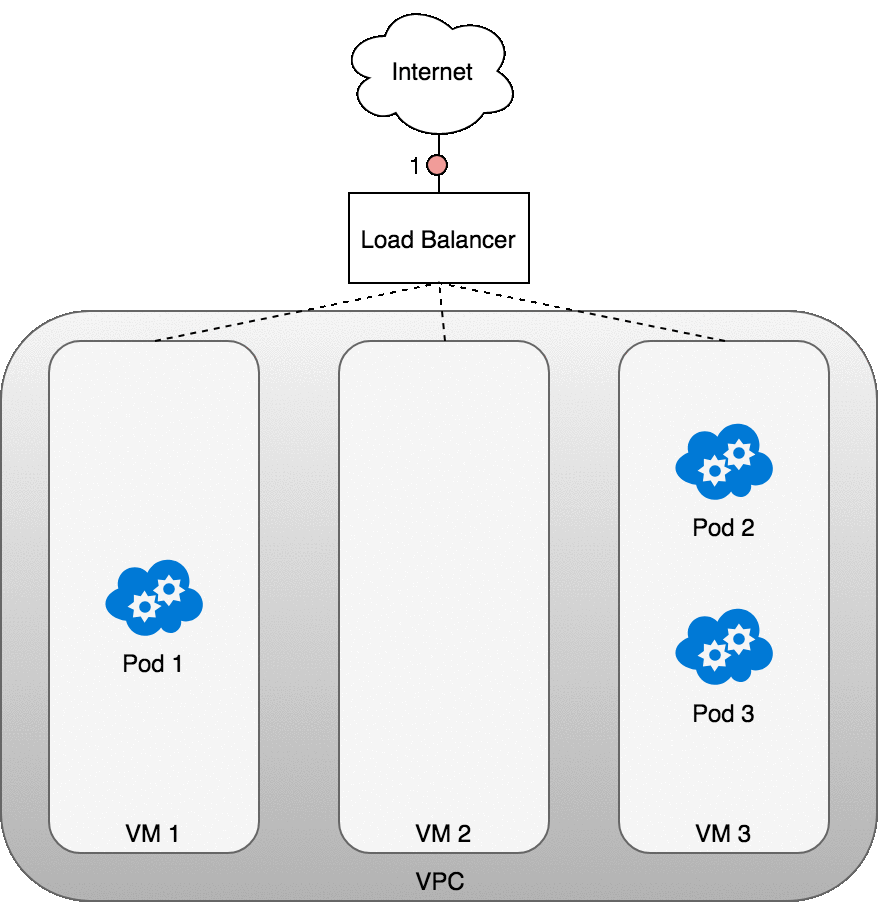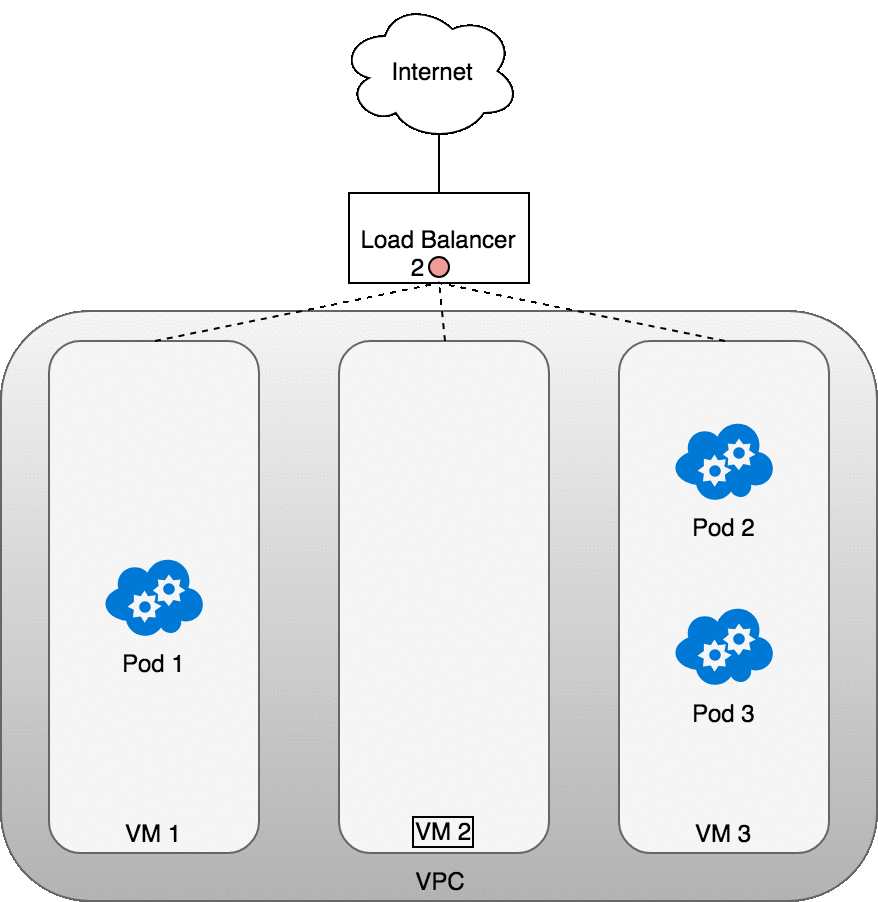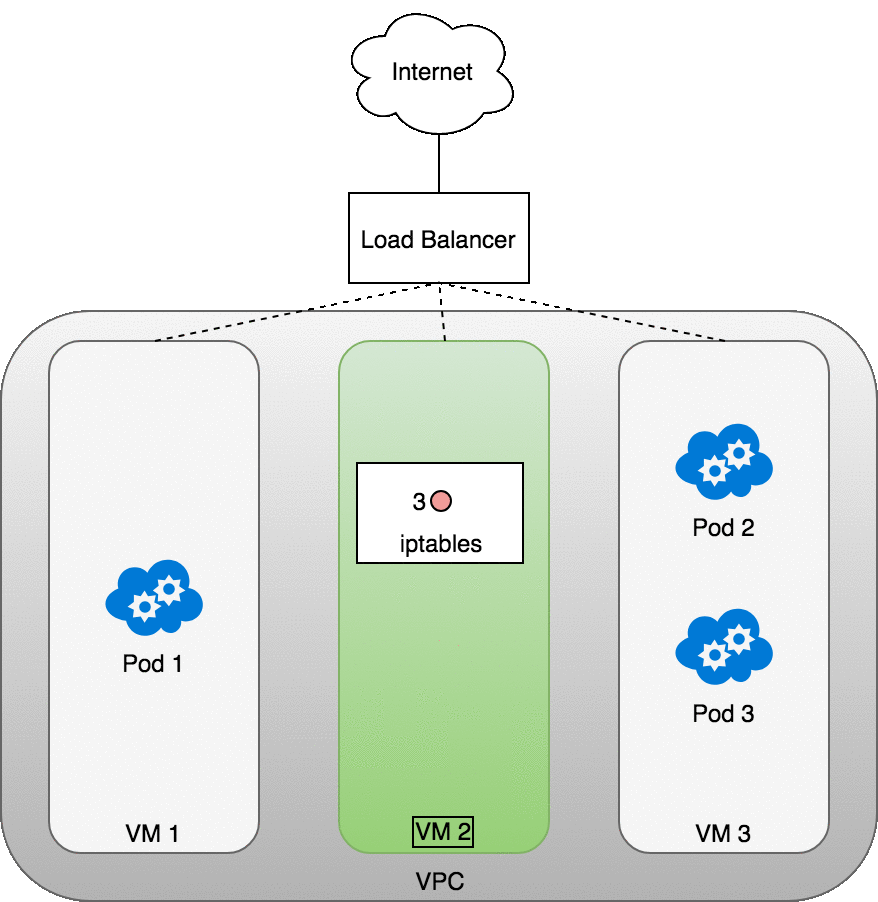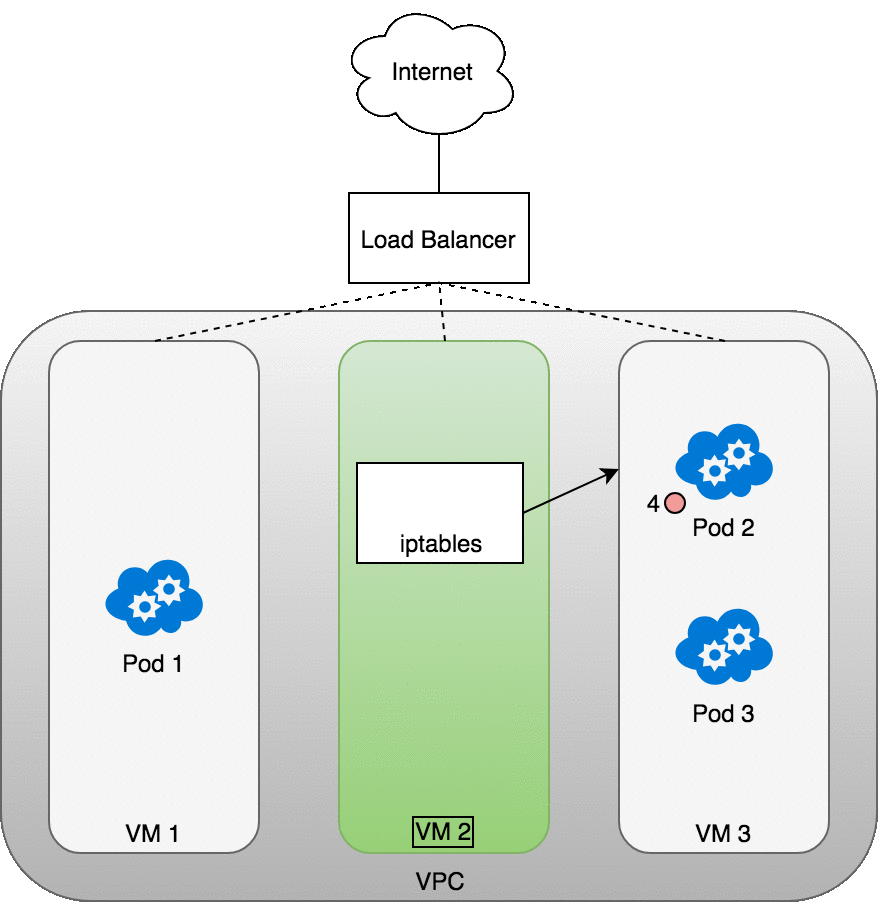
Figure 9: 数据包从 Internet 发送到 Service
如上图所示,当 LoadBalancer 收到数据包后 (2) ,会 随机 选择一个 VM ,图中选择了无任何 Pod 运行的 VM2 (3) 。
VM2 上的 IPTABLES 再使用 NAT 将数据转发至正确的 Pod 上 (4) 。
5.2.2 Ingress controller (L7)
使用 Ingress 的前提是需要先创建 NodePort Service ,它也是由云提供商实现,工作在 7 层并感知 HTTP/HTTPS 协议,将 HTTP 请求映射到 Services 。
Ingress 和 L4 LoadBalancer 类似,只能知道 Node 的 地址,不能感知 Pod 的 IP 信息。
Ingress 和 Node 之间的连接由 Service 的 nodePort 决定。
5.2.2.1 AWS Ingress controller 设计 2
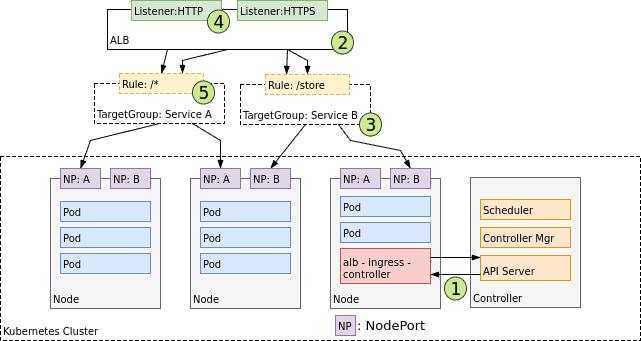
Figure 10: AWS 的 Ingress controller 设计