Netty 内存管理
{Back to Index}
Table of Contents
虽然笔者写这篇文章用尽了心血,但是还是推荐脚注1的文章,写得确实好。
1 堆外内存1
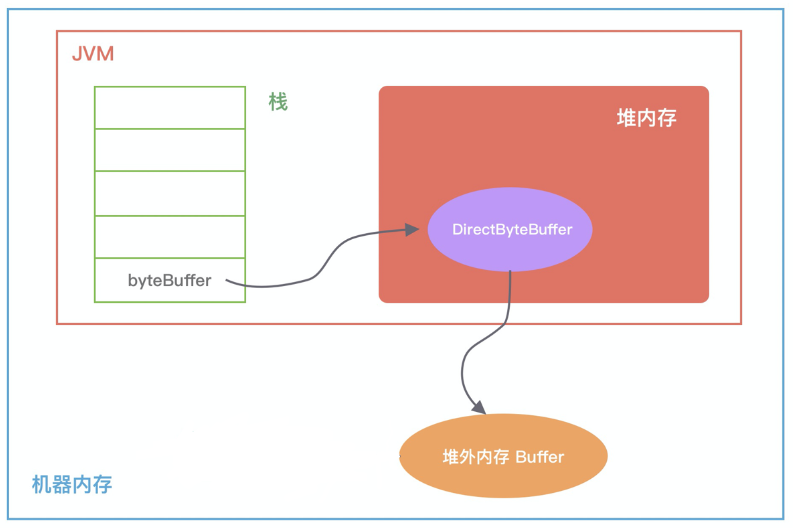
Figure 1: DirectByteBuffer byteBuffer = ByteBuffer.allocateDirect(10 * 1024 * 1024); 内存分布
在堆内存放的 DirectByteBuffer 对象并不大,仅仅包含堆外内存的地址、大小等属性,同时还会创建对应的 Cleaner 对象,通过 ByteBuffer 分配的堆外内存不需要手动回收,它可以被 JVM 自动回收。
当堆内的 DirectByteBuffer 对象被 GC 回收时,Cleaner 就会用于回收对应的堆外内存。
【内存回收】
DirectByteBuffer 对象有可能长时间存在于堆内内存,所以它很可能晋升到 JVM 的老年代, 这时候 DirectByteBuffer 对象的回收需要依赖 Old GC 或者 Full GC 才能触发清理。 如果长时间没有 Old GC 或者 Full GC 执行,那么堆外内存即使不再使用,也会一直在占用内存不释放,很容易将机器的物理内存耗尽。
为了在使用 DirectByteBuffer 时避免物理内存被耗尽,可以通过 JVM 参数 -XX:MaxDirectMemorySize 指定堆外内存的上限大小,当堆外内存的大小超过该阈值时,就会触发一次 Full GC 进行清理回收, 如果在 Full GC 之后还是无法满足堆外内存的分配,那么程序将会抛出 OOM 异常。
此外在 ByteBuffer.allocateDirect 分配的过程中,如果没有足够的空间分配堆外内存,在 Bits.reserveMemory 方法中也会主动调用 System.gc() 强制执行 Full GC, 但是在生产环境一般都是设置了 -XX:+DisableExplicitGC ,因此 System.gc() 是不起作用的,所以不要依赖 System.gc() 。
1.1 Cleaner
DirectByteBuffer 在初始化时会创建一个 Cleaner 对象,它会负责堆外内存的回收工作,Cleaner 属于 PhantomReference ,与引用队列 ReferenceQueue 一起使用,并在 GC 时发挥作用。
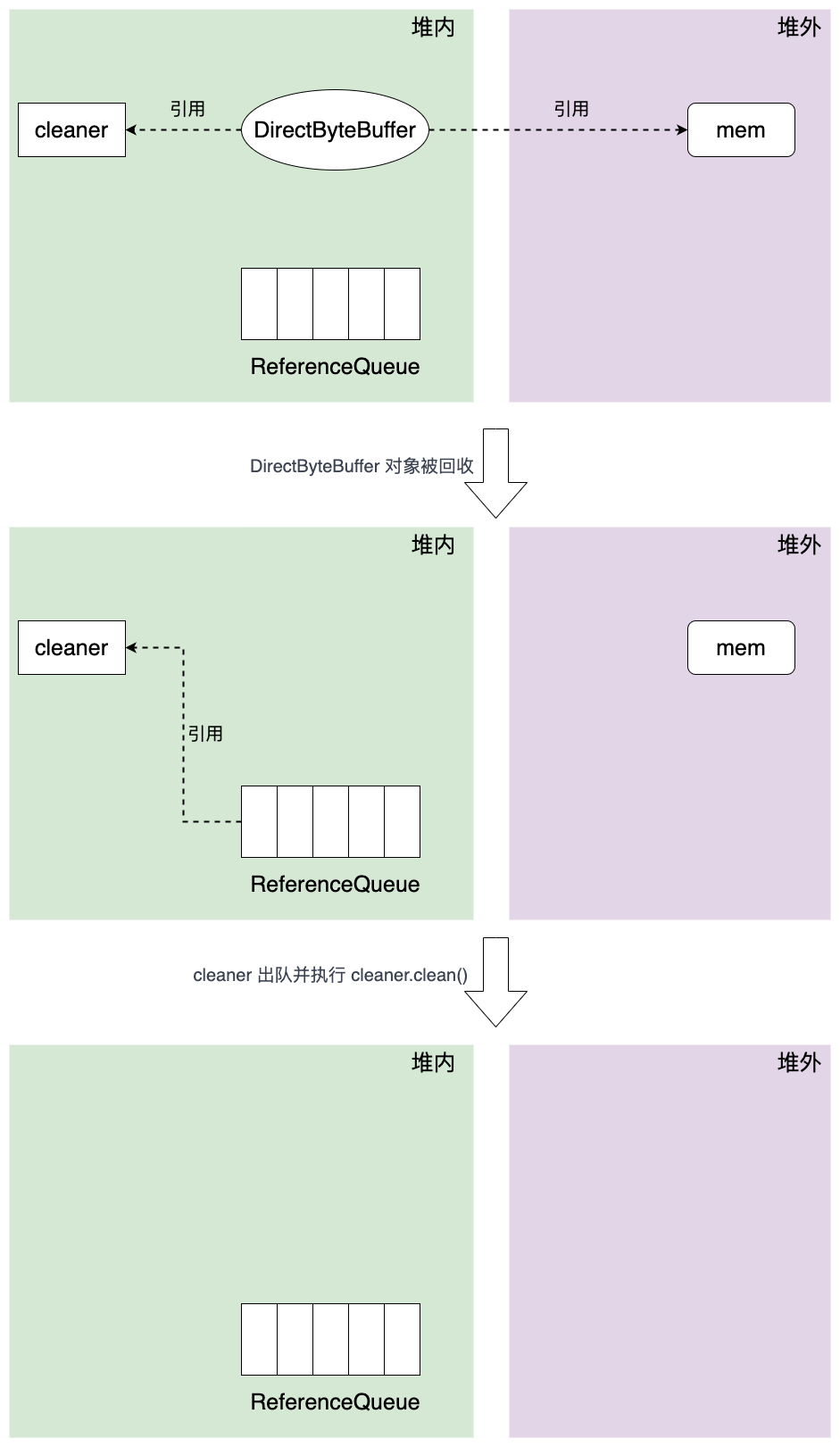
Figure 2: 堆外内存回收原理
如上图所示,当初始化堆外内存时,DirectByteBuffer 对象包含堆外内存的地址,大小以及 Cleaner 对象的引用 ,ReferenceQueue 用于 保存需要回收的 Cleaner 对象。
当发生 GC 时,DirectByteBuffer 对象被回收,此时 Cleaner 对象不再有任何引用关系, 在下一次 GC 时 ,该 Cleaner 对象将被添加到 ReferenceQueue 中,由此,监控线程得到改 cleaner 对象并执行 clean() 方法,clean() 方法主要工作就是调用 unsafe.freeMemory 以清理堆外内存。
2 内存池设计思想
初看 Netty 内存池管理真的是相当得懵,一方面是 Netty 针对这块没有官方文档,另一方面如果不了解内存管理,比如 jemalloc ,很难把握设计思路的主线,就会迷失在源码中。
以下是阅读源码后我对 Netty 内存池管理的简单理解:
2.1 为什么需要内存池
如果没有内存池,在 I/O 负载高的情况下,堆内存频繁分配与释放,GC 压力变大,而 GC 又会带来 Stop-The-World 。就算使用堆外内存,off-heap 内存的创建也是比较慢的。
2.2 最好使用堆外内存
因为最终写到 socket 缓存的时候是以堆外内存的形式,如果是 heap 内存,则需要一次堆外到对内的拷贝,而直接使用堆外内存就省了这次拷贝操作。
2.3 内存是由 Arena 负责创建与维护的
2.4 Arenas 是均匀的分散给 EventLoop 使用的 (作为 thread local)
这么做是因为多线程操作同一个 arena 存在锁的竞争,而将 arena 分散开来使用可以缓解这种竞争。 另外多线程同时从 Netty 中申请内存的操作,从底层来看是多核 CPU 操作同一块内存(在大内存中划分/预留小内存)进行读写。因为由于操作系统的 读写内存屏障(比如 lock 指令会锁住总线) 存在,会导致多个线程的读写并不能做到真正的并行,因此分散 arena 的做法也是为了提升效率。
线程和 PoolArena 是 多对一 的关系。
Arena 是分而治之思想的体现,与其让一个线程管理全部内存,倒不如将任务派发给多个线程,每个线程独立管理,减少相互干涉的概率(线程竞争)。
2.5 为什么要 PoolThreadCache
一方面是上面提到的缓存 arena 引用,另一方面是因为借鉴了 tcmalloc (thread cache malloc) 的思路,即使用完毕的内存不交还给 arena ,而是缓存在线程本地缓存中。当线程需要申请内存时,如果能从本地缓存中找到,说明这原本就是属于该线程之前创建并使用过的内存,别的线程感知不到该内存,直接用即可。如果不使用线程缓存而是直接还给 arena 的话,就会存在线程竞争,因为 arena 分配内存的关键代码是加锁的。
2.6 为什么需要 memoryMap 和 depthMap
为了高效的内存分配与回收,并减少 Page 碎片(空闲的,可被使用的 Page 内存),本质是实现了 Netty 版的 Buddy 算法。
2.7 为什么要搞一堆 subpagePools 数组
为了提高内存使用率,主要是针对小块内存,减少内存碎片(已被分配的 Page 内的碎片),本质是实现了 Netty 版的 slab 算法。
3 内存管理术语
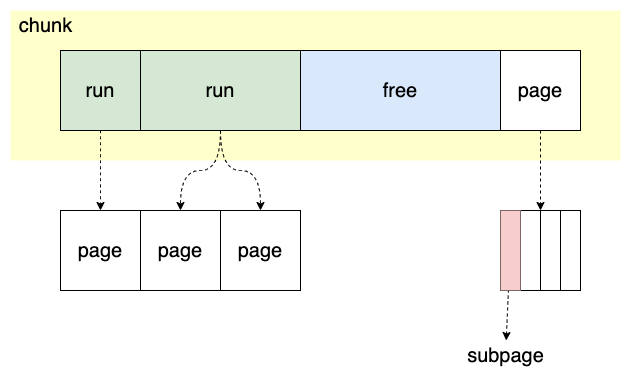
Figure 3: 数据结构示意图
chunk
Netty 向操作系统申请内存的最小单位 (默认 16M) ,是 run 的集合
run
对应一块连续的内存,大小是 page 的倍数
page
chunk 的最小分配单元,默认大小为 8K ,一个 chunk 默认有 2048 个 page
subpage
负责 page 内的内存分配,目的是为了减少内存碎片。因为如果需要分配的内存小于 page 的大小,如只有 32B ,直接分配一个 page 的话非常浪费
handle
用于表示 poolChunk 中一块内存的位置,大小,使用情况等信息
private long toHandle(int bitmapIdx) { return 0x4000000000000000L | (long) bitmapIdx << 32 | memoryMapIdx; // 加 0x4000000000000000L 是为了让高 32 位不全是 0 }
低位的 4 个字节 (memoryMapIdx) 表示当前 page (8K) 在 PoolChunk (16M) 中 memoryMap 映射数组中的下标索引;
高位的 4 个字节 (bitmapIdx) 则表示当前需要分配的内存 PoolSubPage 在 page (8K) 内存中的位图索引。
4 Unsafe ByteBuf
ByteBuf 不仅可以用堆内堆外区分,也可以用是否池化 (Pooled/Unpooled) 来区分。
另外也可以从第三个维度来区分:是否支持 unsafe 优化。
unsafe 对内存的操作更快(基于内存地址+偏移量的方式),但并非所有平台都支持。是否支持 unsafe 是由代码自动判断的 (检查 JDK 底层是否有 unsafe 对象)。
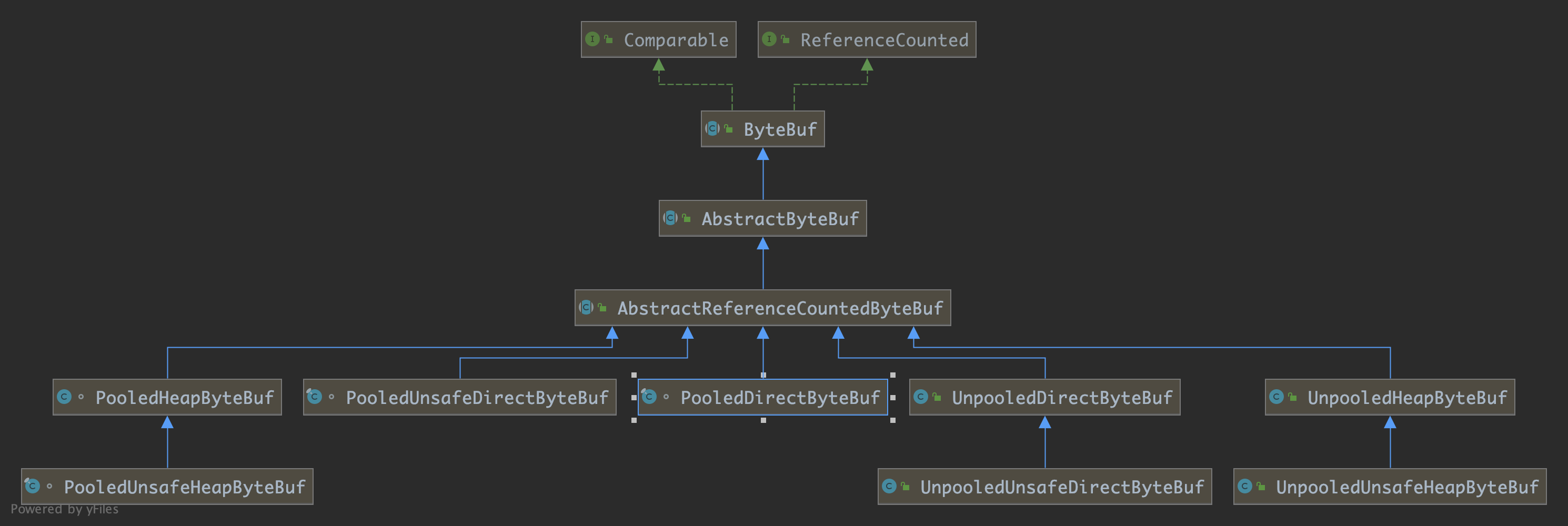
Figure 4: ByteBuf 层次关系(维度)
5 ByteBufAllocator 内存分配逻辑
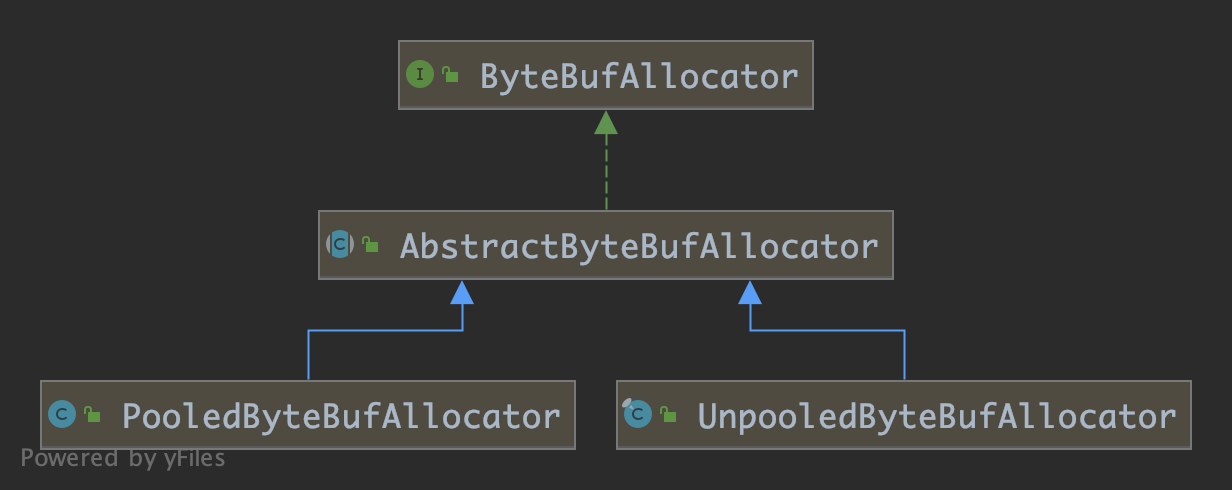
Figure 5: ByteBufAllocator 层级关系
5.1 UnpooledByteBufAllocator
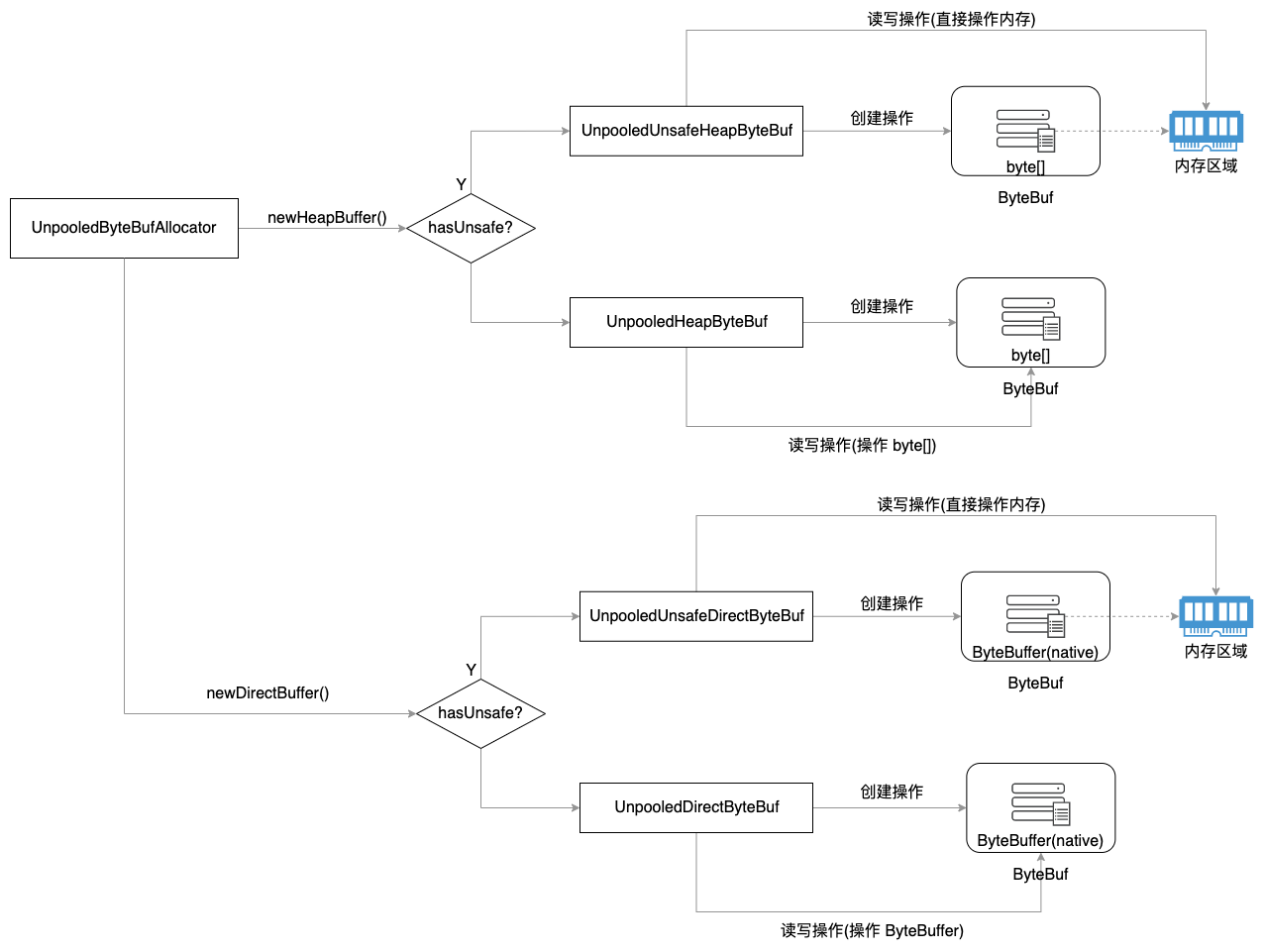
Figure 6: Unpooled 根据是否支持 unsafe 的内存分配逻辑
5.2 PooledByteBufAllocator

Figure 7: PooledByteBufAllocator 层级关系
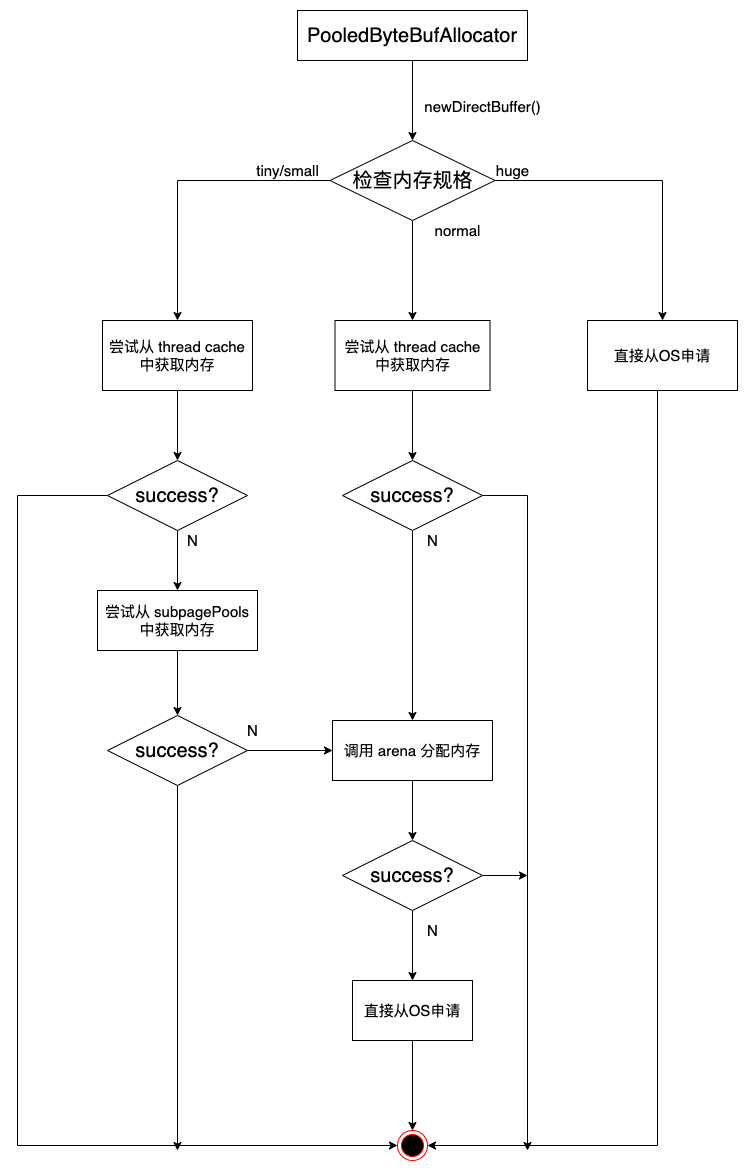
Figure 8: Pooled 内存分配逻辑
6 PoolThreadCache 【想象成二级缓存】
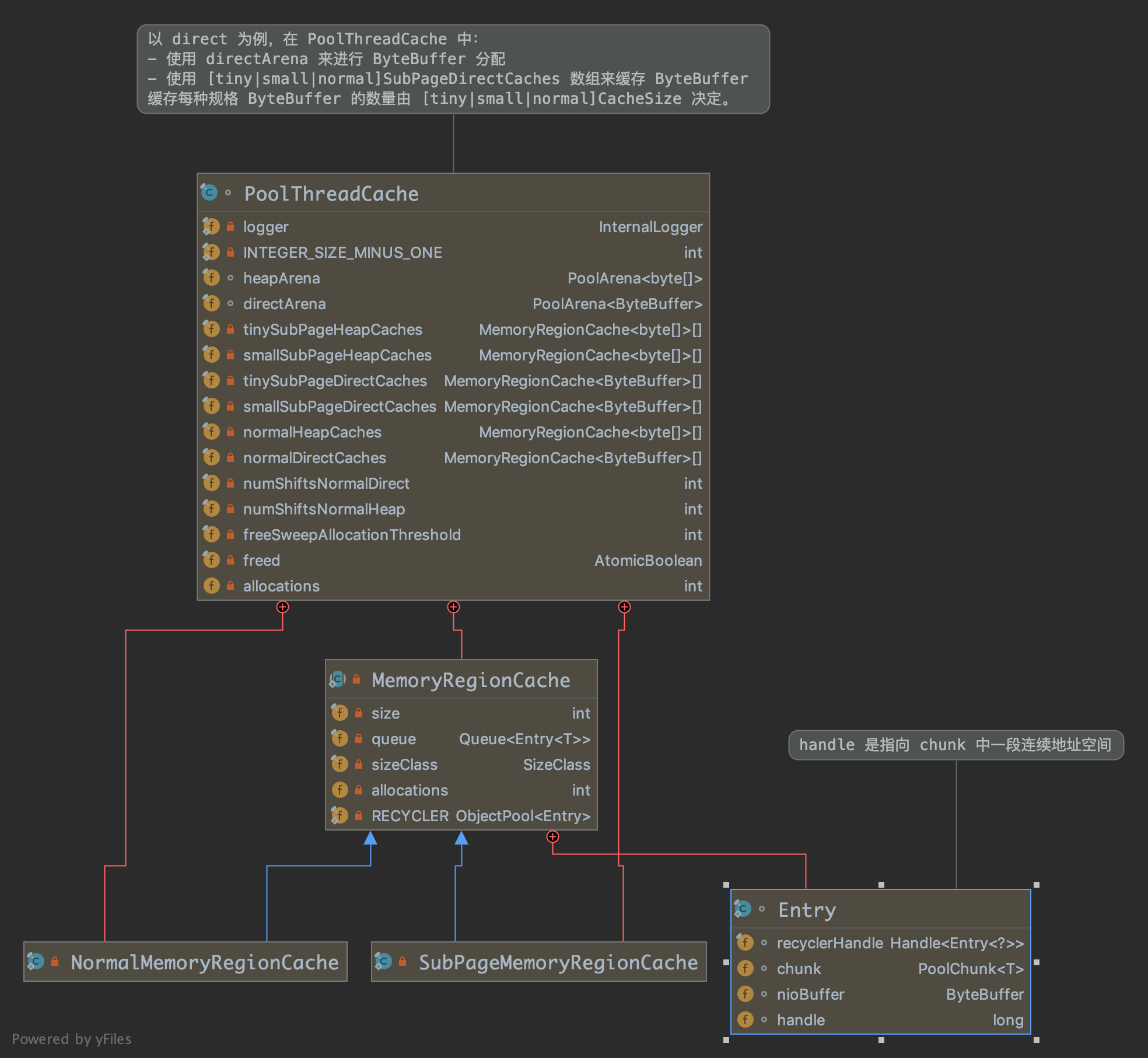
Figure 9: 类组织关系
如下图所示,在 PooledBytebufAllocator 内部维护着 directArena 和 heapArena 数组。
当线程(EventLoop)需要分配内存时(尚无线程本地缓存),会通过 PoolThreadLocalCache 获取到专属于该线程的 directArena 或 heapArena 来进行分配工作。
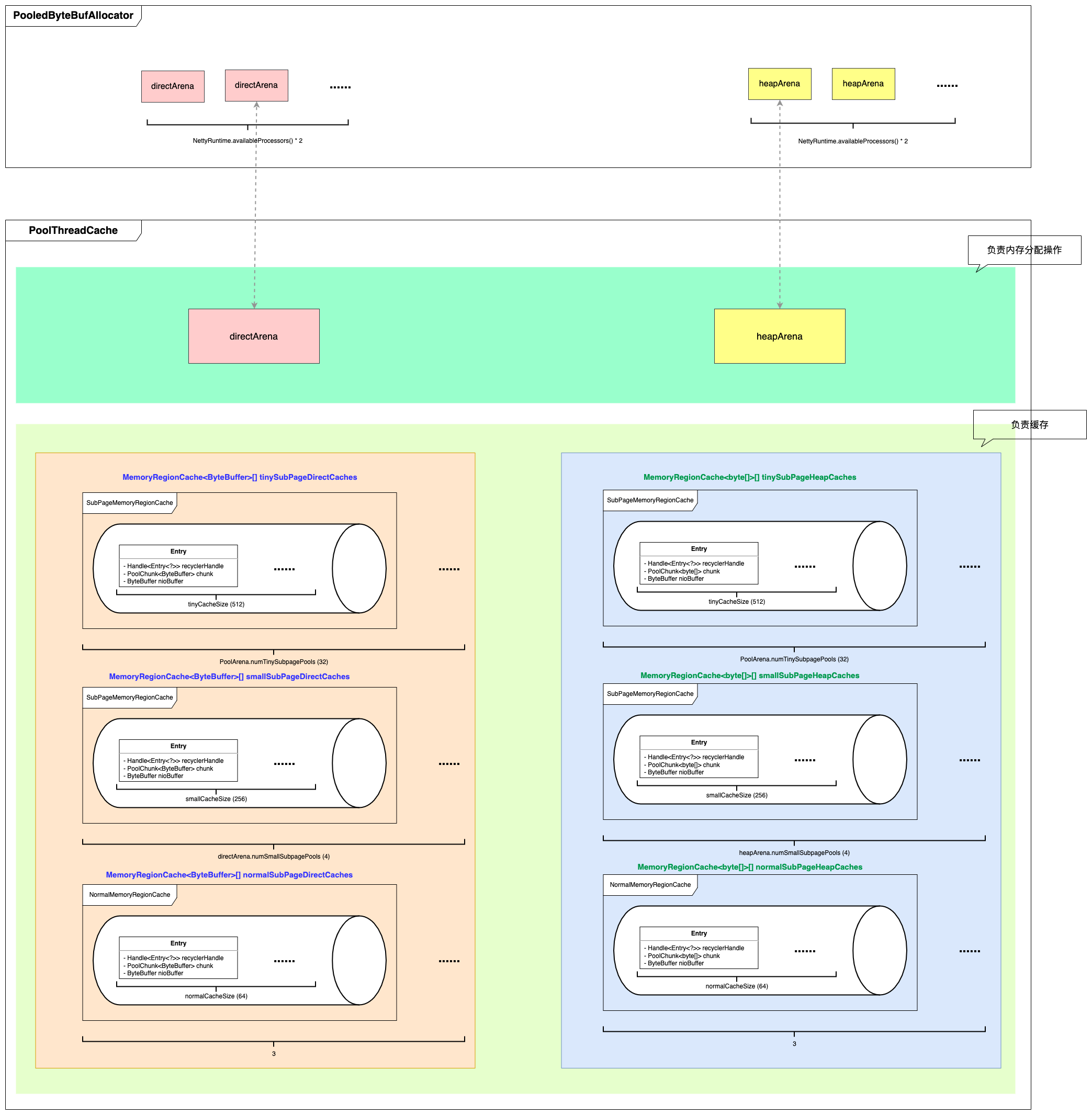
Figure 10: PooledByteBufAllocator 与 PoolThreadLocalCache 内存结构
因此 PoolThreadCache 内部主要维护了 两部分内容 :
一个是 arena,包括 directArena 和 heapArena (通过 PoolThreadLocalCache#leastUsedArena 方法从 PooledBytebufAllocator 的 arena 数组中选取一个 被使用最少的 arena )。
另一部分就是不同规格大小的 cache 队列(用来缓存 已被分配出来的,且用完后不还给 arena 的内存 )。
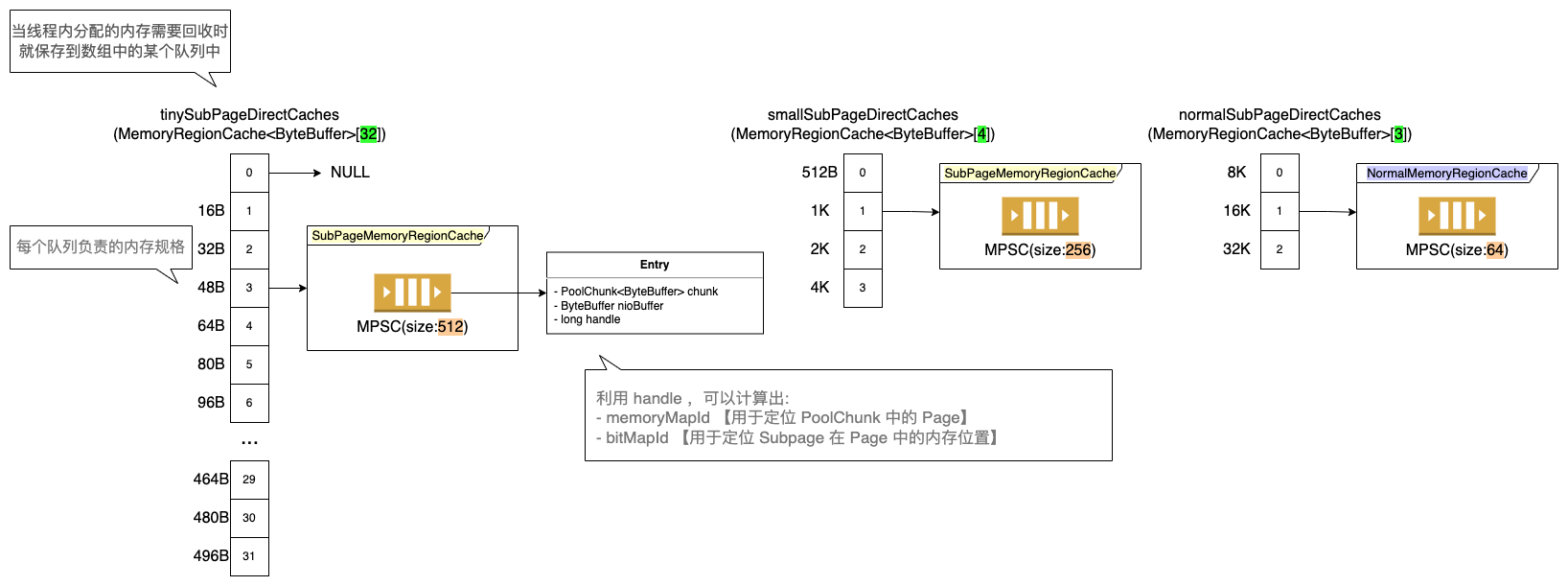
Figure 11: PoolThreadLocalCache 内部缓存数据结构 【以 directMemory 为例】
PoolThreadCache 的初始化过程跟踪
6.1 内存缓存大小规格
Netty 以 Chunk (16M) 为单位向操作系统申请内存。所有的分配操作都是在 Chunk 中进行。
使用 Page 对 Chunk 进行内存切分,可以切分出 2048 个 Page 。
Page 也可以使用 SubPage 再进行切分,比如需要 1K 的内存,则可以将 Page 切分成 8 个 SubPage ,每个 SubPage 是 1K ;
如需要 512B 的内存,则可以将 Page 切分成 16 个 SubPage ,每个 SubPage 是 512B 。
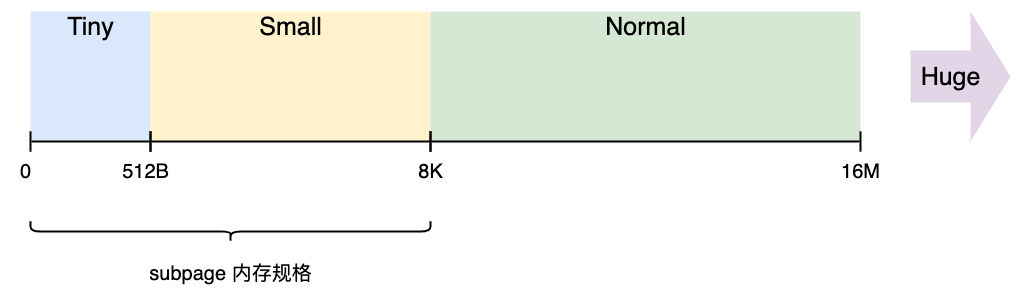
Figure 12: 内存规格
Netty 会针对每种相同规格的内存进行缓存,如上图所示,以 tinySubPageDirectCaches 数组为例,虽然该数组有 32 个元素,但是 每个元素缓存的内存规格是不一样的 ( tiny 数组的一个元素是不使用的 )。
Huge 内存不做缓存、不做池化,直接以 Unpool 的形式分配内存,用完后回收。 (每次请求分配内存时会单独创建特殊的非池化 PoolChunk 对象,当对象内存释放时整个 PoolChunk 内存也会被释放)
不在 normal 缓存规格内的内存块用完后将不会被缓存,直接还给 PoolArena 。
此外,如果数组元素对应的队列满后,用完的内存也不会被缓存,也是直接还给 PoolArena 。
通过调试代码来可以看出 ByteBuf 释放后在数组中缓存的位置:
ByteBuf byteBuf = PooledByteBufAllocator.DEFAULT.directBuffer(1024, Integer.MAX_VALUE); byteBuf.release();
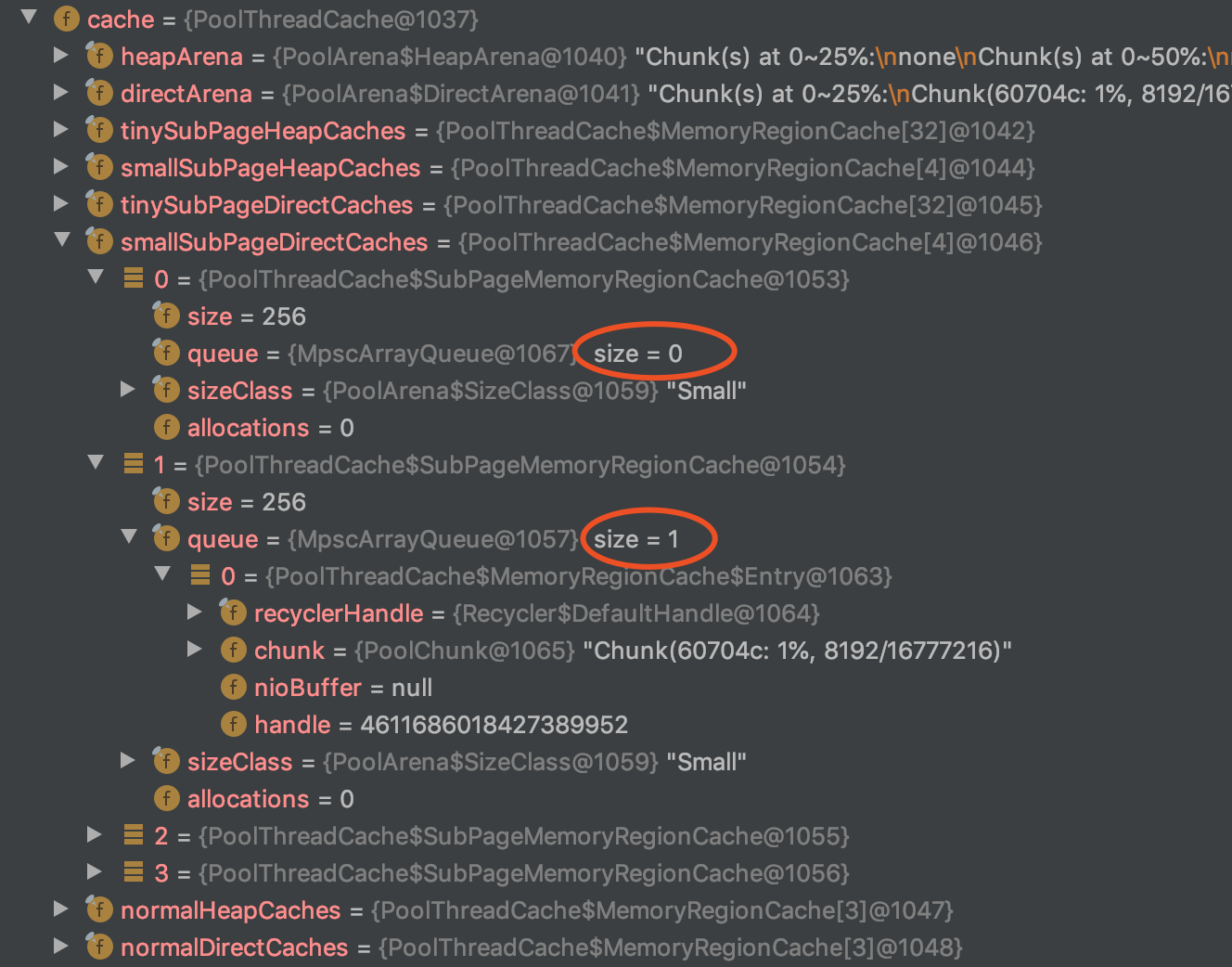
Figure 13: 在 ByteBuf release 后 smallSubPageDirectCaches[1] 【1K 规格】 中缓存了这块内存
7 PoolArena 【想象成一级缓存】
7.1 内部存储结构
Arena 内部管理的内存块为 Chunk , 申请大于 Chunk 大小的内存将直接向系统申请。
Chunk 内部由 n 个 page 组成,page 还可以切分为 n 个 SubPage 。
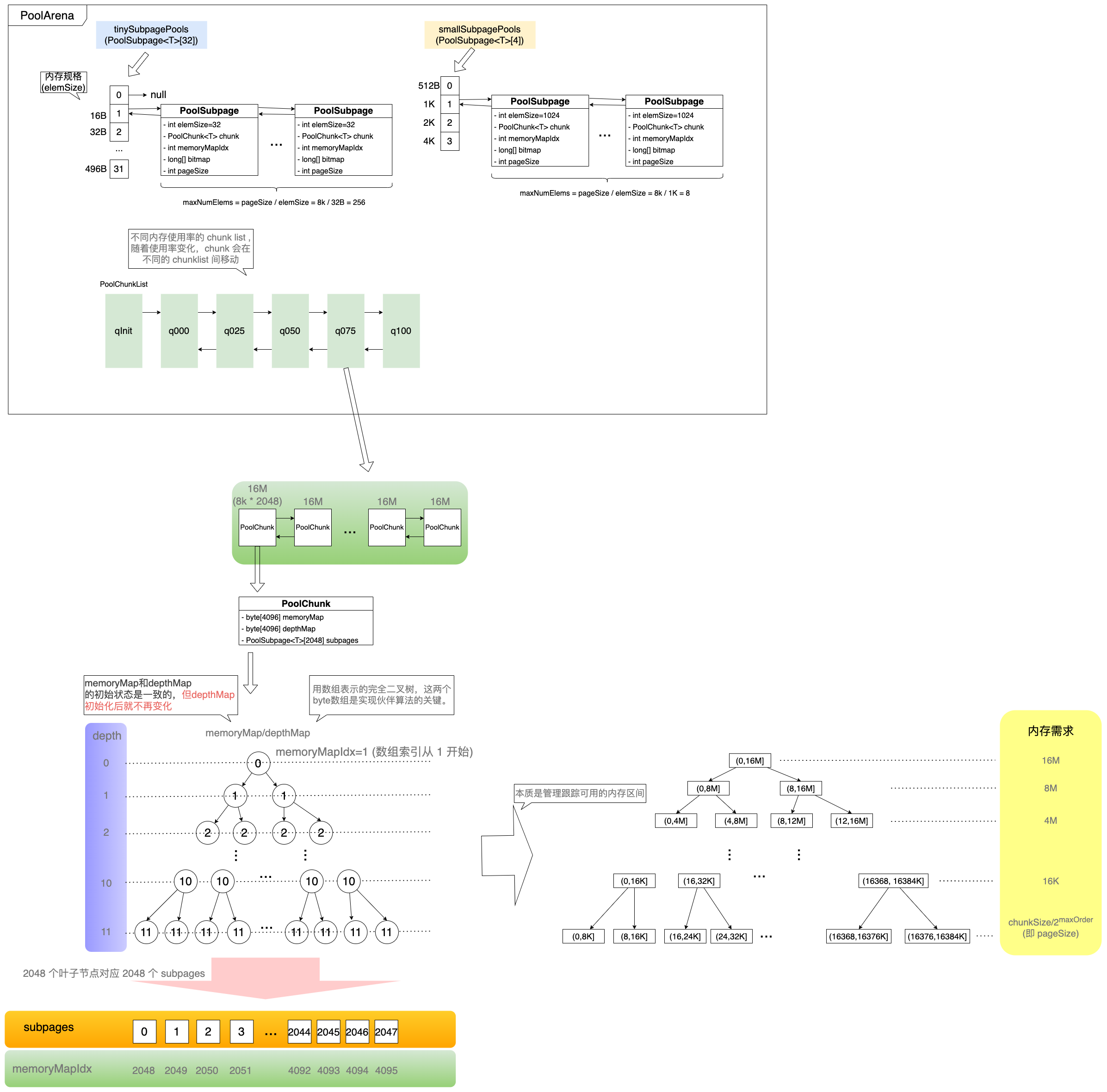
Figure 14: PoolArena 的内部数据结构
7.1.1 Chunk & ChunkList
Arena 内部还对 Chunk 做了 使用量的监测 。
Arena 内部有 6 个 ChunkList 分别为:qInit, q000, q025, q050, q075, q100 。
它们依次组成一个双向链表,分别有一个 最小使用量 和 最大使用量 的阀值。
// PoolChunkList<T> nextList, int minUsage, int maxUsage, int chunkSize q100 = new PoolChunkList<T>(null, 100, Integer.MAX_VALUE, chunkSize); q075 = new PoolChunkList<T>(q100, 75, 100, chunkSize); q050 = new PoolChunkList<T>(q075, 50, 100, chunkSize); q025 = new PoolChunkList<T>(q050, 25, 75, chunkSize); q000 = new PoolChunkList<T>(q025, 1, 50, chunkSize); qInit = new PoolChunkList<T>(q000, Integer.MIN_VALUE, 25, chunkSize);
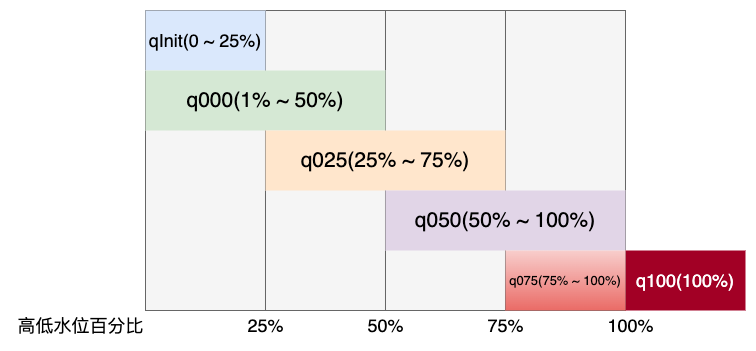
在每次 allocate 和 deallocate 时判断 Chunk 是否触及阀值,然后分别上移/下移到合适的 ChunkList 。
为了减小内存碎片, 分配的优先级如下:
q050 > q025 > q000 > qInit > q075
q000 这个 PoolChunkList 是没有前向节点的 。这是因为当其余 PoolChunkList 没有合适的 PoolChunk 可以分配内存时,会创建一个新的 PoolChunk 放入 pInit 中,然后根据用户申请内存大小分配内存。
而在 p000 中的 PoolChunk ,如果因为内存归还的原因,使用率下降到 0% , 则不需要放入 pInit ,而是直接执行销毁方法 ,将整个内存块的内存释放掉即可。
7.1.2 Page
Chunk 由 2048 个 Page 组成,一个 Page 默认 8k 。
Chunk 里面将这 2048 个 page 用其 2 倍空间(4096)的 memoryMap 数组 以完全二叉树管理 。
memoryMap[0] 未使用,实际使用 memoryMap[1:] 总共 4095 个元素。
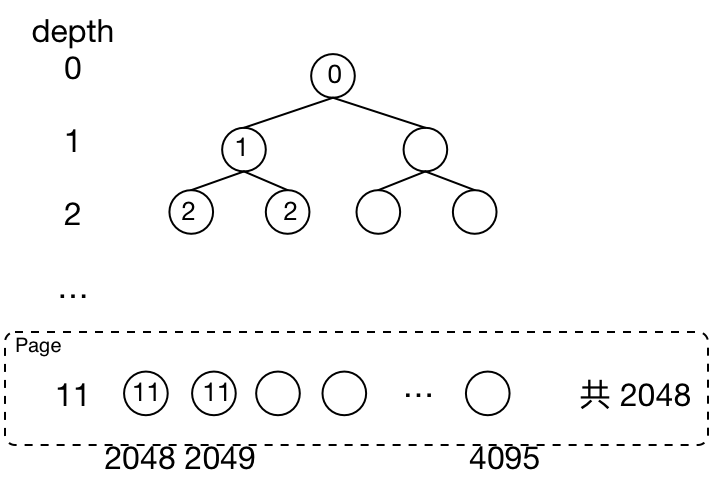
Figure 16: memoryMap 的布局
深度为 11 的共 2048 个元素表示该 page 有没有被分配。每个节点的 value 默认为该节点在树的深度。
等某个节点被分配掉,会将自己的 value 设为 12,并递归地更新所有父节点的 value 。
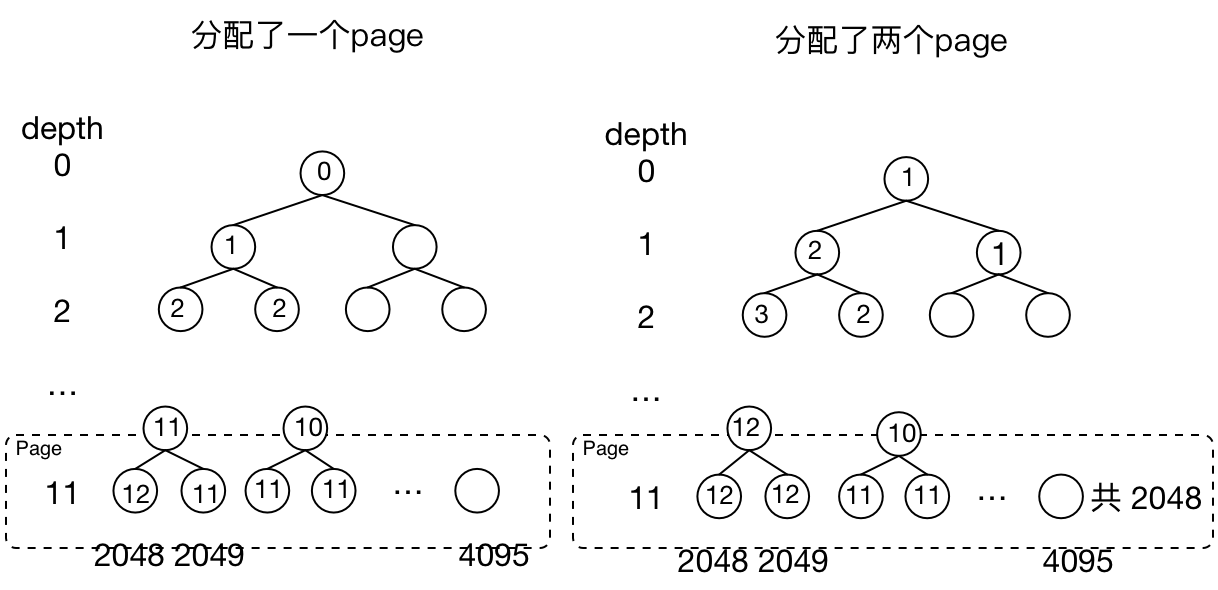
Figure 17: 每次被分配后都要同时更新自己的 parent 的 value, parent 的 value 取 2 个 child 中小的一个
比如当要分配 8K 的大小时直接去第 11 层找第一个 val 为 11 的节点,找到后更新自己以及 parent 节点。
又当比如需要分配 8MB 内存时,找第 1 层的 2 个节点, 只要节点的 value 不等于 depth 就知道该节点的 child 被分配过了。
\(memoryMap[i] = depthMap[i]= depth\)
表示该节点下面的所有叶子节点都可用,这是初始状态。可以把 depth 理解为规模,表示可以分配出 \(>= depth\) 级别的内存。
\(memoryMap[i] = depthMap[i] + 1\)
即 \(memoryMap[i] > depth\) ,表示该节点下面有一部分叶子节点被使用,但还有一部分叶子节点可用。 也表示可以分配出 \(> depth\) 级别的内存,比如 i 为10 ,depth 为 11 ,说明可以分配出 11 (8K) 级规模的内存,但 10 (16K) 级的分配不了,因为已经有一个子节点已经分配了。
\(memoryMap[i] = maxOrder + 1 = 12\)
表示该节点下面的所有叶子节点不可用。
7.1.3 SubPage
Subpage 的作用是用来标识分配小于一个 page 的内存块。但是 Subpage 不再是用二叉树管理,而是用更方便的方式 (bit map)。
一个 Subpage 只能分配一种 size 大小,然后用一个长度为 3 的 Long 型数组作为 bit map 来管理 最多 512 个标识 。 比如如果 page 为 8K ,由于最多 512 个标识可用,所以最小分配单元 为 16B ;如果最小分配单元为 32 B ,则只需要 256 个标识即可。
Subpage 也是一个链表, 相同规格的 subpage 链在一起。 PoolArena 用数组维护了 Subpage 的链表头(如下代码所示),每次新创建 Subpage 会把 subpage 链到对应索引位置的 PoolSubpage 头结点后面 。
private final PoolSubpage<T>[] tinySubpagePools; // 每个元素都是链表头 private final PoolSubpage<T>[] smallSubpagePools;
7.2 申请内存逻辑
主要流程如下:(之前的章节有流程图,这里仅做简单总结)
- 创建一个 PooledByteBuf 该 buf 仅仅是一个对象,字段都是初始值, 不能直接使用 。创建过程使用了 Recycler 进行优化,即这个 buf 可能是对象池回收的也可能是新创建的。
优先从 PoolThreadCache 的缓存数组中 获取缓存住的内存
如果有缓存的内存,则用来初始化上一步的 buf 。
使用 directArena 分配内存
如果 PoolThreadCache 中没有缓存的内存,则由 directArena 进行分配 (该 directArena 属于该 PoolThreadCache )。并将分配的内存给 ByteBuf 用于初始化,这样就完成了一次内存申请的过程。
源码跟踪
7.2.1 Page 级别的内存分配 【buddy】
Page 级别内存的分配核心逻辑是在 PoolChunk#allocateRun(int normCapacity) 完成,返回的就是 memoryMap 内存映射的索引值,也就是数组的下标。
大致步骤如下:
- 尝试在现有的 Chunk 上分配
- 否则创建一个新的 Chunk
- 用申请到的内存来初始化 PooledByteBuf
源码跟踪
7.2.2 SubPage 级别的内存分配 【slab】
SubPage 级别内存的分配核心逻辑是在 PoolChunk#allocateSubpage(int normCapacity) 完成,返回一个 handle ,这是一个 64 位的标记,记录内存地址信息(bitmapIdx 和 memoryMapIdx ,合并成一个 long 类型)。
PoolSubpage 中直接采用位图 (bitmap) 管理空闲空间,因为不存在申请连续空间的说法,所以申请释放相对简单。
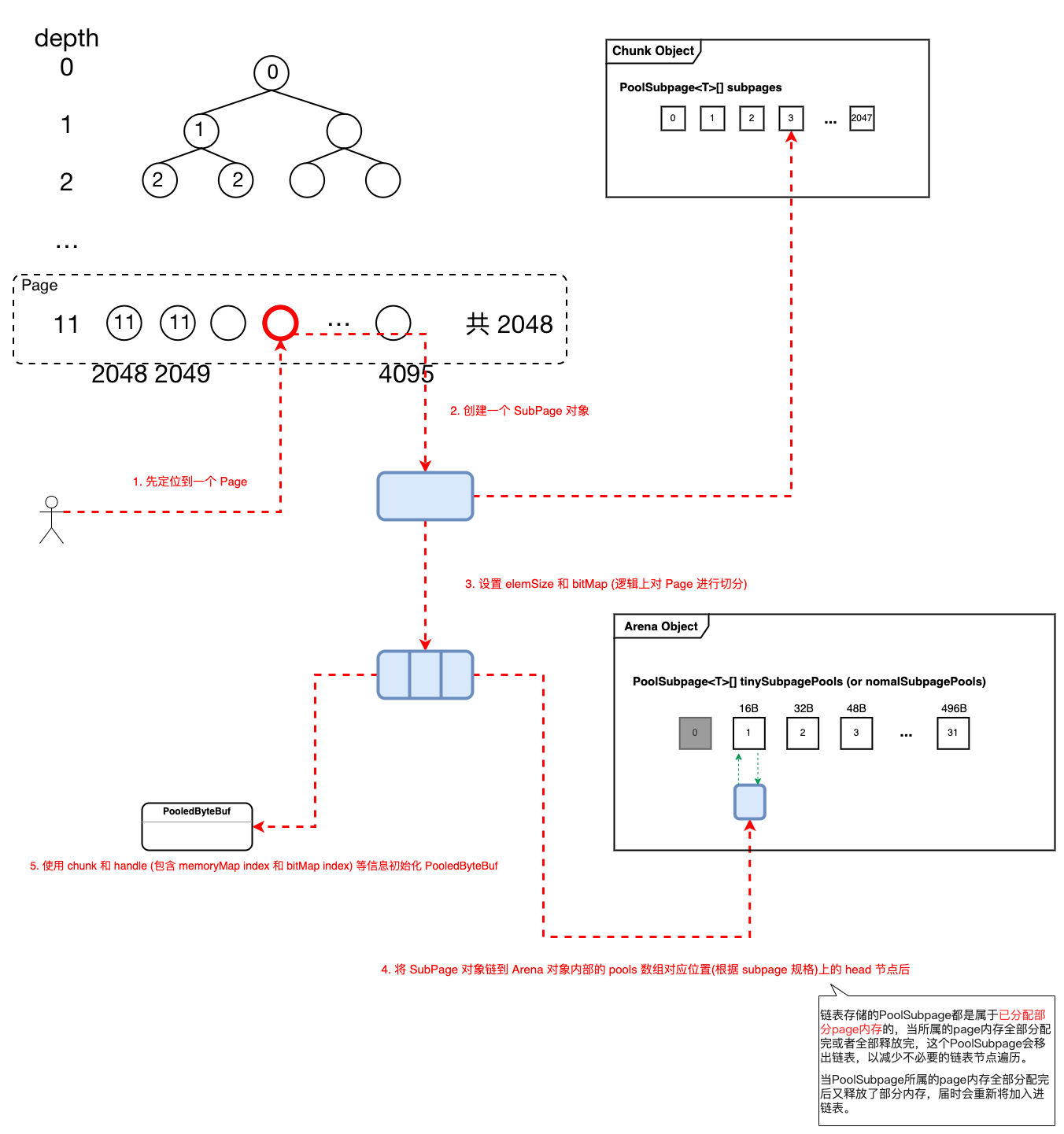
Figure 18: SubPage 级别内存分配主要步骤
源码跟踪
8 PooledByteBuf 的释放
释放过程主要逻辑:
- 将内存区段加入至 PoolThreadCache 的缓存中
- 如果加入缓存失败(比如缓存满了),则将内存区段标记为未使用(分 Page 和 SubPage 两种情况)
- 将 PooledByteBuf 加入对象池 (Recycler)