TCP
{Back to Index}
Table of Contents
1 TCP 流量控制基本原理 1
2 TCP 滑动窗口 2
3 超时重传时间选择 3
3.1 加权平均往返时间 RTTs 计算
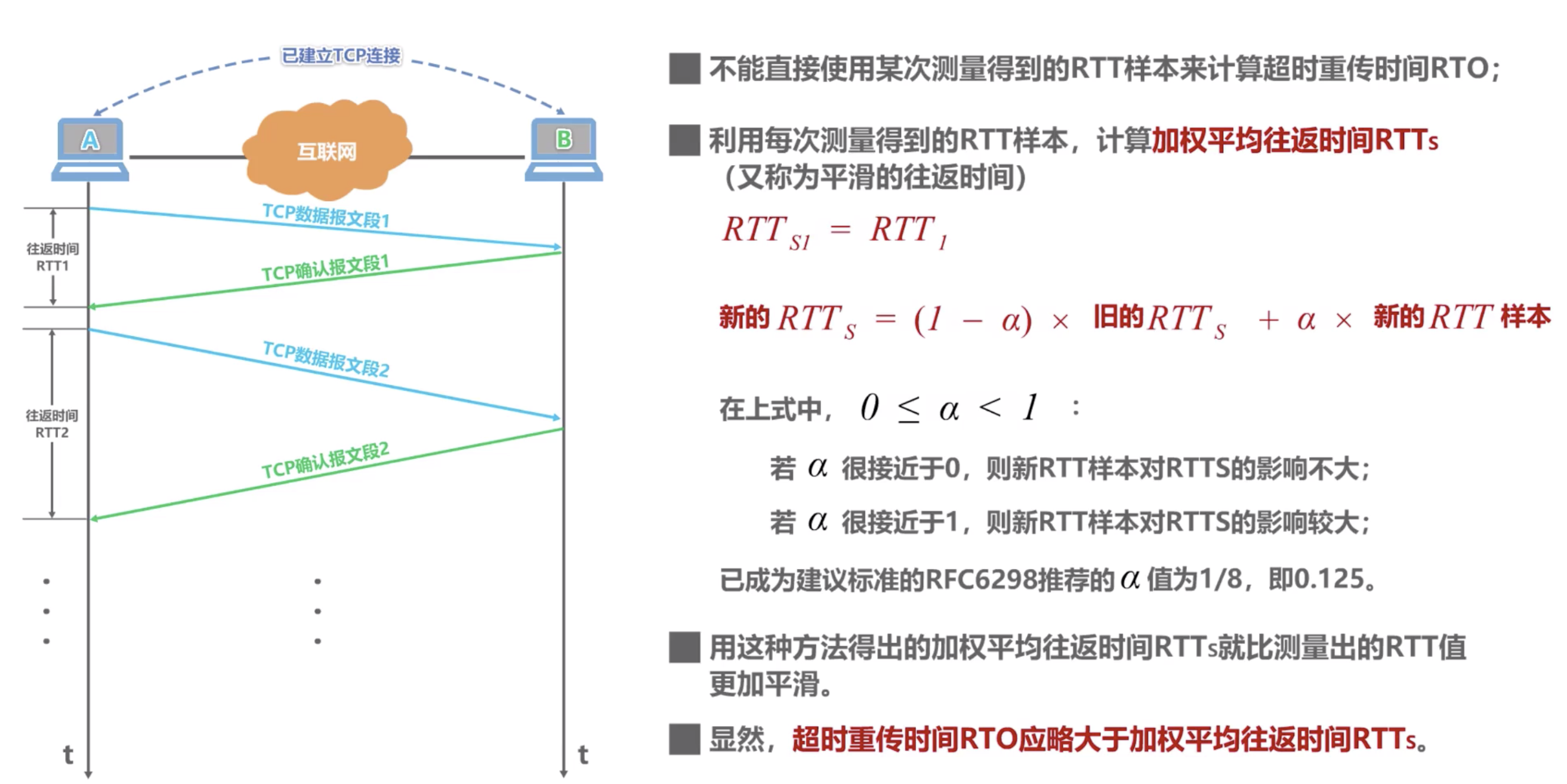
Figure 1: RTTs 计算
3.2 超时重传 RTO 计算

Figure 2: RTO 计算
3.3 超时重传下的 RTT 测量
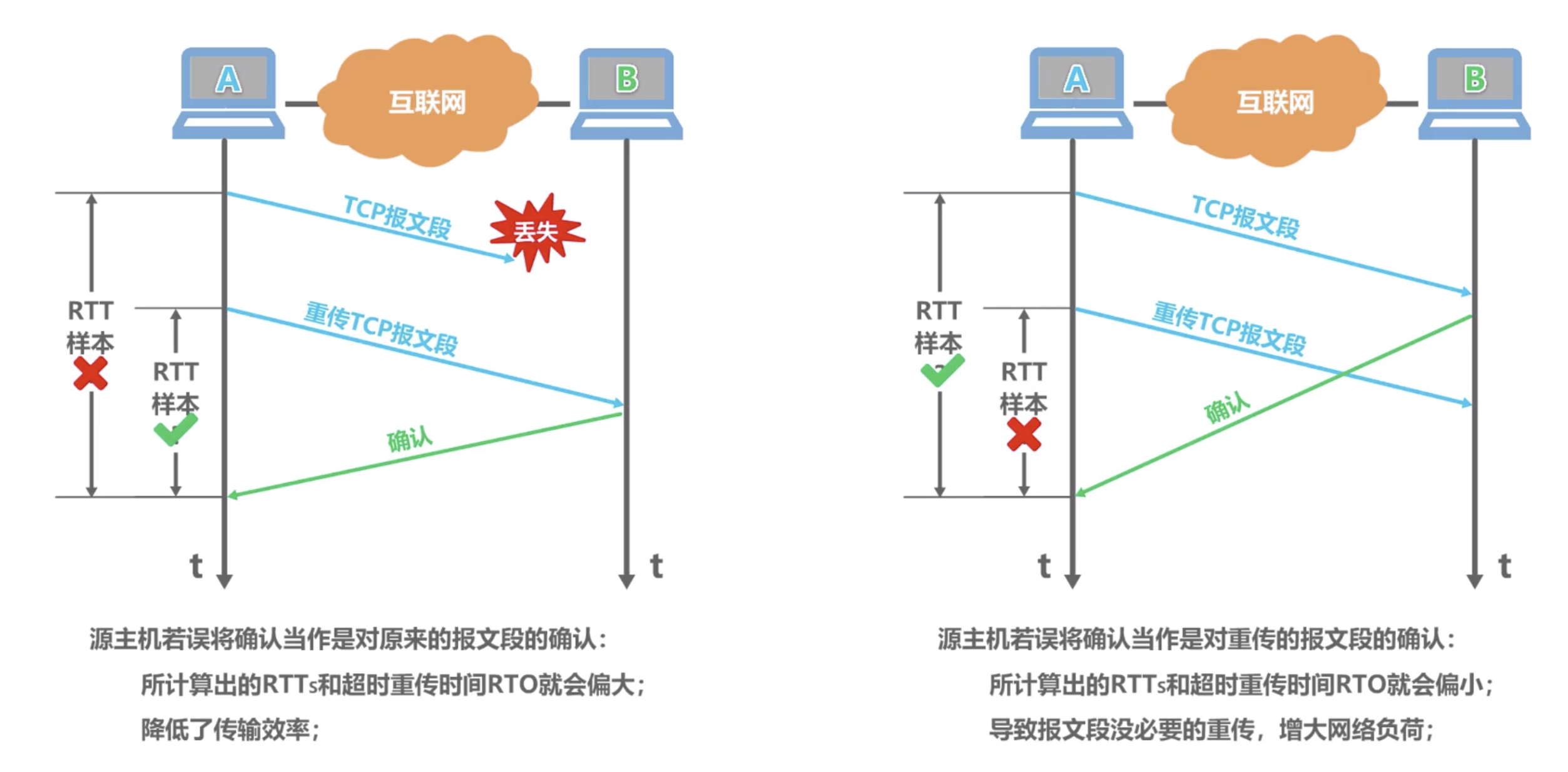
Figure 3: 有超时重传的 RTT 错误测量举例
3.4 修正 Karn 算法
报文段每重传一次,就把超时重传时间 RTO 增大一些,典型做法是将新 RTO 的值取为旧 RTO 值的 2 倍。
3.5 RTO 测量举例
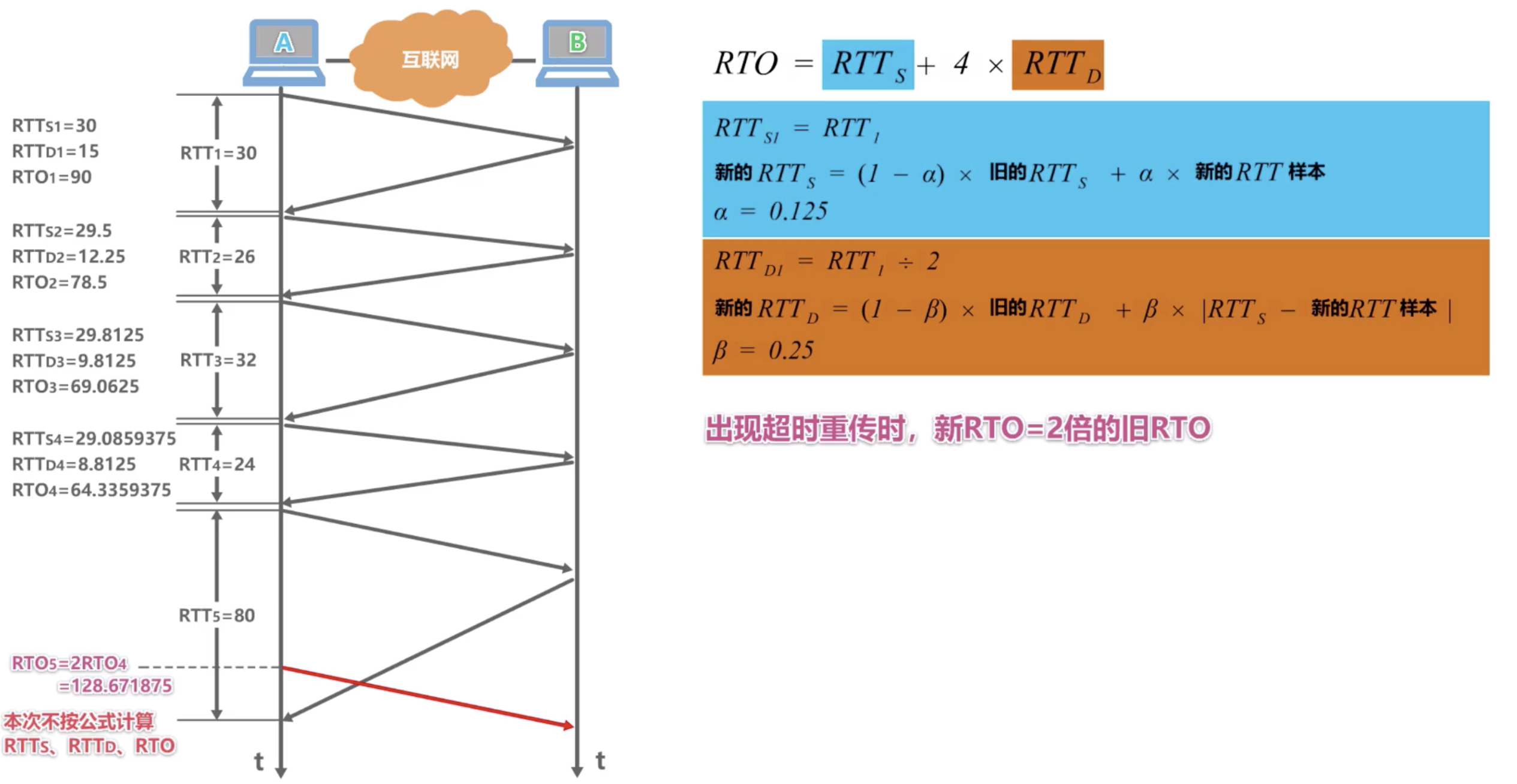
Figure 4: RTO 测量案例
4 拥塞控制 4
在某段时间,若对网络中某一资源(带宽,交换机缓存)的需求超过了该资源所能提供的可用部分,网络性能就要变坏。这种情况就叫做拥塞。
TCP 有四种拥塞控制算法:
- 慢开始
- 拥塞避免
- 快重传
- 快恢复
4.1 拥塞窗口 cwnd
发送方维护一个叫做拥塞窗口 cwnd 的状态变量,其值取决于网络的拥塞程度,且动态变化。
cwnd 的维护原则是只要没有出现拥塞,窗口就再增大一些,只要网络出现拥塞,窗口就减少一些。
判断出现拥塞的依据是:产生拥塞事件, 即超时或 3 冗余 ACK 。
发送方还要维护一个慢开始门限状态变量 ssthresh :
- 当 cwnd < ssthresh ,使用慢开始算法
- 当 cwnd > ssthresh ,停止使用慢开始算法而该用拥塞避免算法
- 当 cwnd = ssthresh ,既可使用慢开始算法也可使用拥塞避免算法
4.2 Tahoe
- 慢开始是指 一开始向网络中注入的报文段少 ,并不是指 cwnd 增长速度慢
- 拥塞避免并非指完全能够避免拥塞,而是指在拥塞避免阶段将 cwnd 控制为按线性规律增长,使网络不易出现拥塞
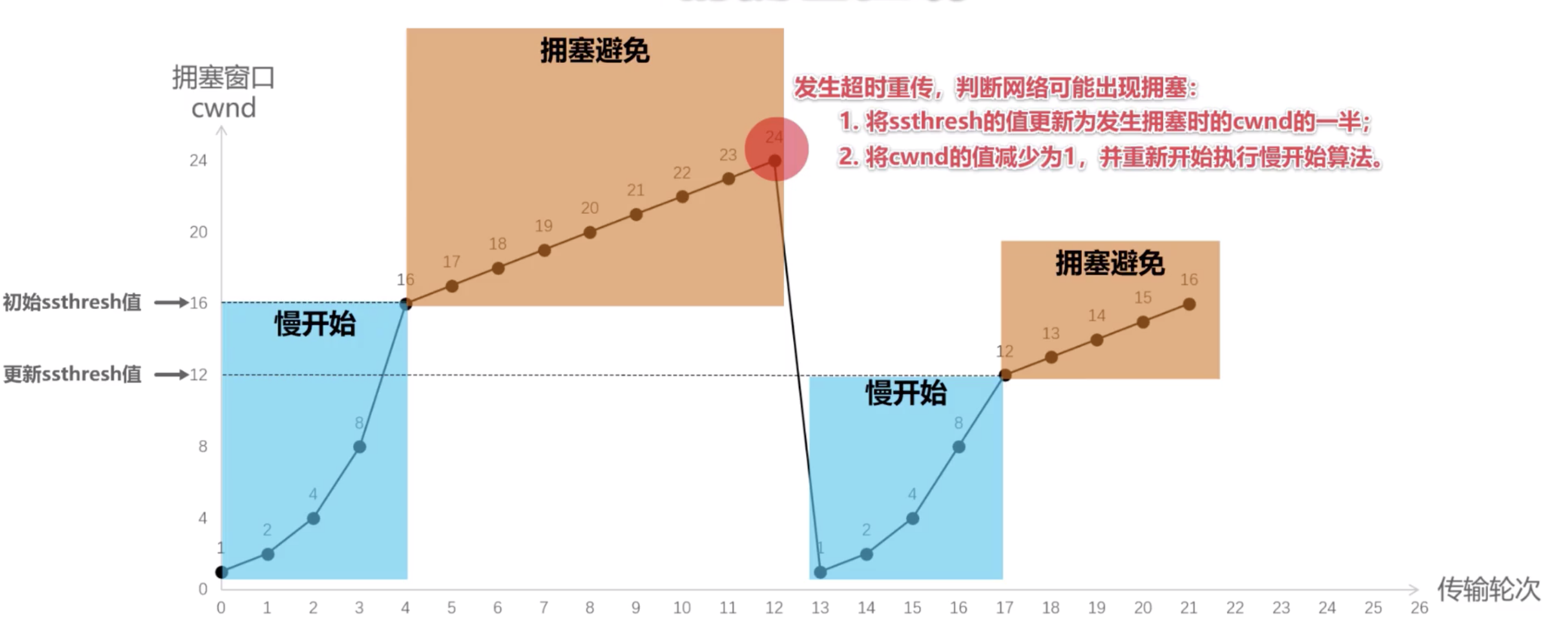
Figure 5: 慢开始和拥塞避免算法
Tahoe 算法涉及两个状态:
- SS(Slow Start)
- 该状态下,每个 RTT ,cwnd 翻倍
- 如果遇到拥塞事件( 即 timeout 或 3 dup ack ),重传【超时重传(timeout 情况)或是快速重传(3 dup ack 情况)】数据包,同时 cwnd 降为 1 MSS ,ssthresh = cwnd/2 ,仍维持在 SS 状态中
- 当 cwnd 达到 ssthresh ,进入 CA 状态
- CA(Congestion Avoidance)
- 该状态下,每个 RTT ,cwnd 增加 1 MSS
- 如果遇到拥塞事件,重传数据包,同时 cwnd 降为 1 MSS ,ssthresh = cwnd/2 ,退回 SS 状态
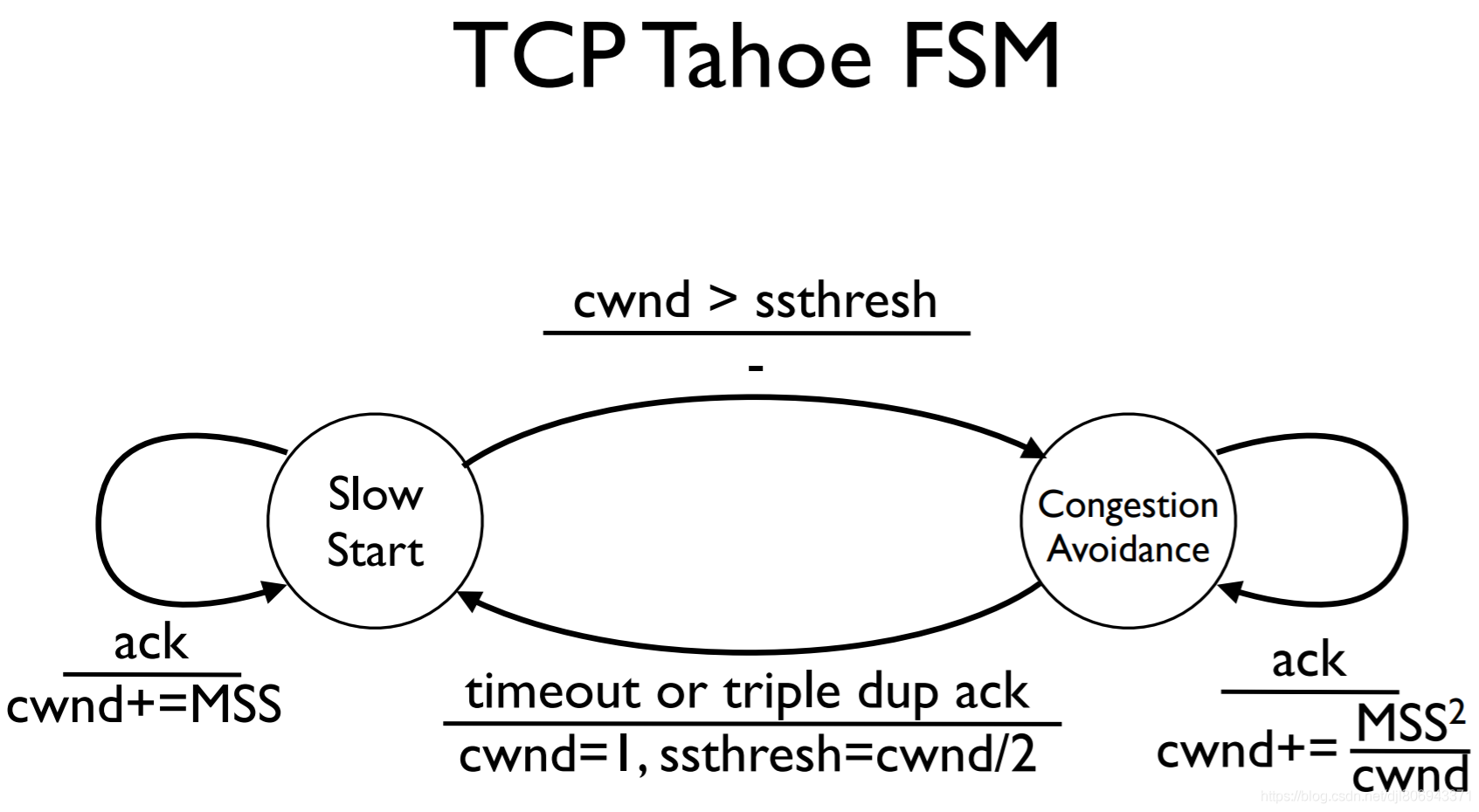
Figure 6: Tahoe FSM
Tahoe 的问题在于如果是 3 dup ack 的情况下,直接将 cwnd 降为 1 MSS 太武断了。
4.3 Reno5
有时,个别报文会在网络中丢失,但实际并未发生拥塞。这将导致发送方超时重传,并 误认为 网络发生了拥塞。
发送方一旦收到 3 个重复确认,就知道现在只是丢失了个别报文段,于是不启动慢开始算法,而是执行快恢复算法。
发送方将慢开始门限 ssthresh 值和 cwnd 值调整为 当前窗口的一半 ,开始执行拥塞避免算法。
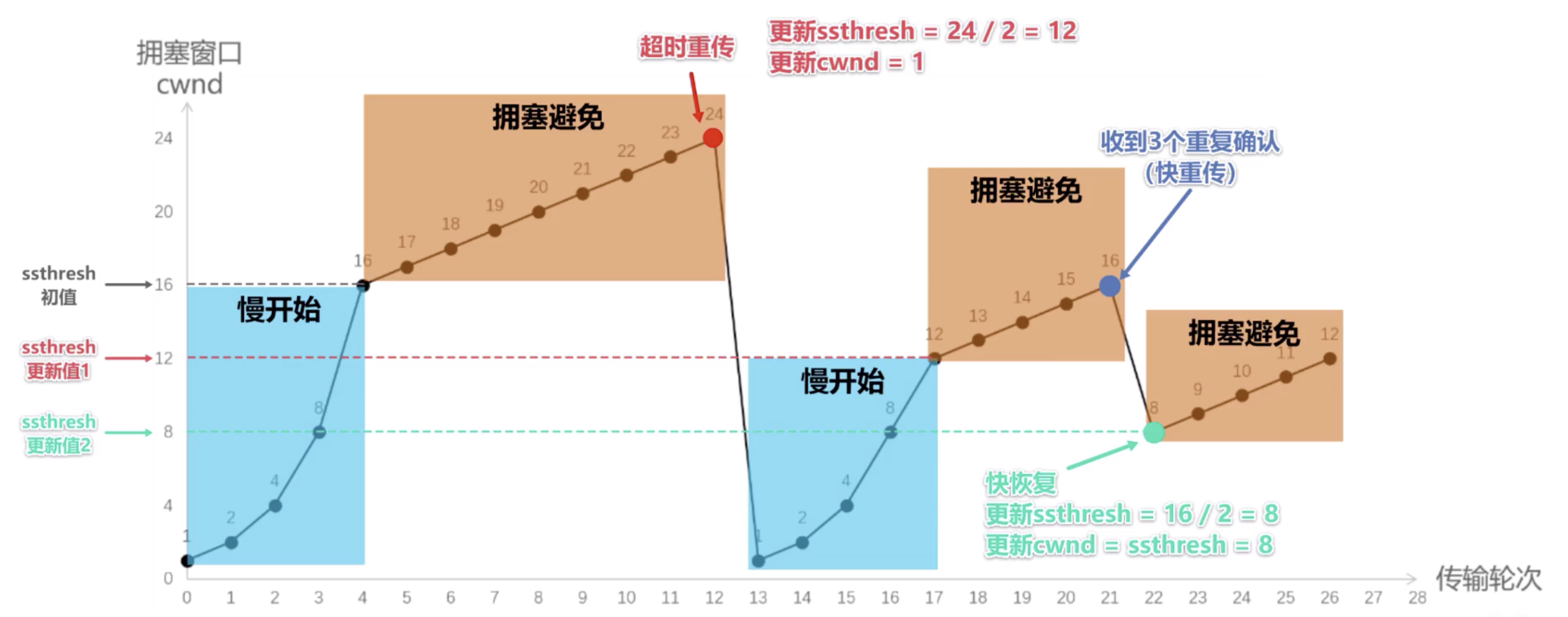
Figure 7: 快重传和快恢复算法
Reno 算法涉及 三个 状态:
- SS (Slow Start)
- 该状态下,每个 RTT ,cwnd 翻倍
- 如果遇到超时事件,超时重传数据包,同时 cwnd 降为 1 MSS ,ssthresh = cwnd/2 ,仍维持在 SS 状态中
- 如果遇到 3 dup ack 事件,快速重传数据包,ssthresh = cwnd/2 ,cwnd = ssthresh + 3 ,进入 FR 状态
- 当 cwnd 达到 ssthresh ,进入 CA 状态
- CA (Congestion Avoidance)
- 该状态下,每个 RTT ,cwnd 增加 1 MSS
- 如果遇到超时事件,超时重传数据包,同时 cwnd 降为 1 MSS ,ssthresh = cwnd/2 ,退回 SS 状态
- 如果遇到 3 dup ack 事件,快速重传数据包,ssthresh = cwnd/2 ,cwnd = ssthresh + 3 ,进入 FR 状态
- FR (Fast Recovery)
- 如收到 dup ack , cwnd += 1MSS
- 如收到 new ack , 进入 CA ,cwnd = ssthresh
- 遇到超时事件,超时重传数据包,同时 cwnd 降为 1 MSS ,ssthresh = cwnd/2 ,退回 SS 状态
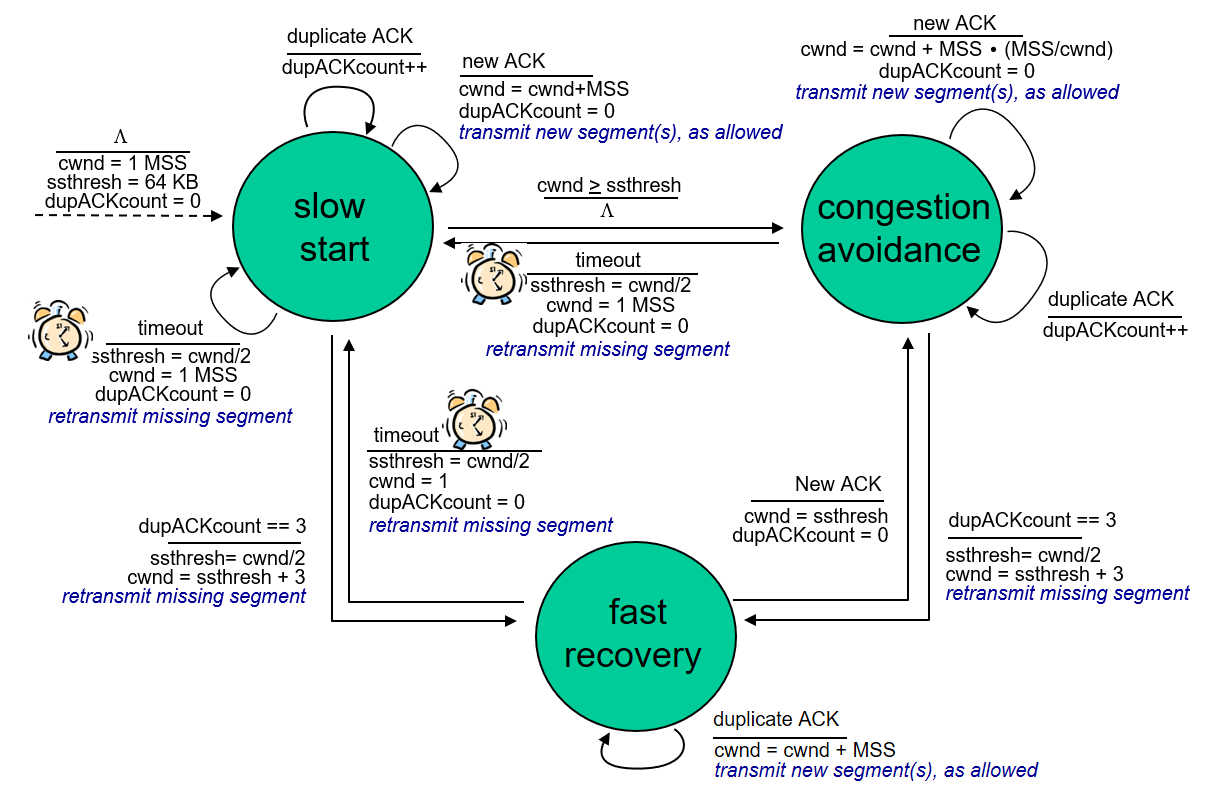
Figure 8: Reno FSM
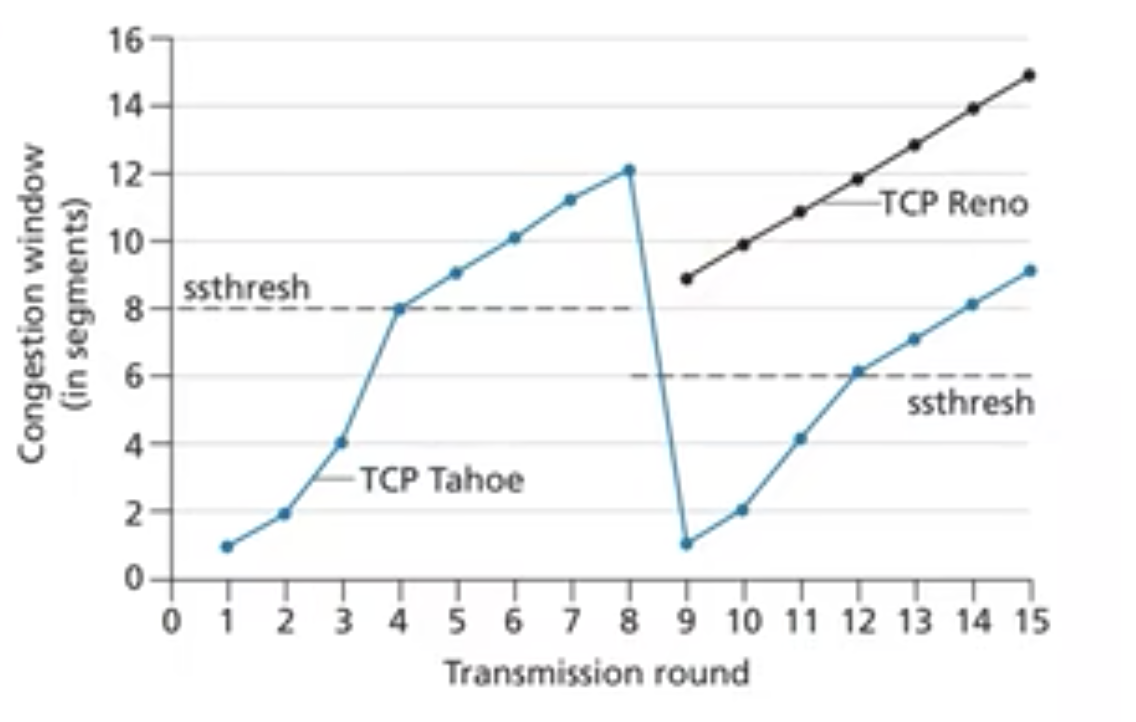
4.4 New Reno
是 Reno 的改进,Reno 适合单个段的丢失,New Reno 适合多个段丢失的情况。在 FR 状态时,会重发所有待确认的段,收到确认后才会进入 CA 状态。
4.5 SACK
SACK 是针对 New Reno 的优化,因为在 new reno 中,一个 RTT 内只能重传一个丢失段,效率较低,而使用 SACK 可以让发送方了解到所有丢失段的信息,这样就可以一并重发,提高效率。
4.6 Vegas
Reno 类算法主要是基于拥塞事件(超时,3 dup ack)来【感知】网络拥塞,而 Vegas 则是通过延迟变化来感知的。
Vegas 算法太【礼貌】了,未发生拥塞时,就提前做出反应,而其他算法都很野蛮,发生拥塞后再反应。
因此只在理想情况(都采用 Vegas 算法)下有很好的表现,在现实中大概率行不通。
4.7 CUBIC
基于丢包反馈的思想, 快速 【追踪】到可用的最大带宽(不拥塞时的最大值)。其慢启动和快速恢复阶段和 reno 算法保持一致,但在 CA 阶段做到快速提升吞吐量。缺点在于试探最大带宽时比较激进,容易造成网络抖动,比如大量的数据涌向网络设备,占满缓存队列。