C/C++
{Back to Index}
Table of Contents
- 1. 运行
- 2. 类型
- 3. 对象
- 4. 多态
- 5. 语法
- 6. 函数
- 7. 智能指针
- 8. 迭代器
- 9. 并发编程
- 10. Memory Order
- 11. C++11
- 12. 设计思想
- 13. 代码示例
1. 运行
1.1. Tool Chain
Tool Chain 是三种元素的集合,按顺序执行,最终将代码转换成可执行程序:
- 预处理器
- 编译器
- 链接器
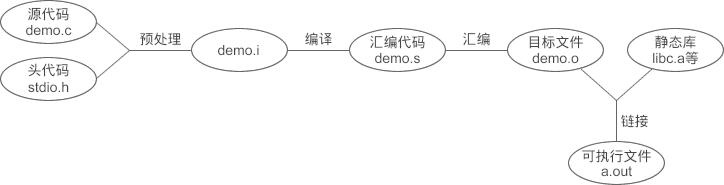
1.1.1. 预处理
在 GCC 中,可以通过下面的命令生成.i文件:
gcc -E demo.c -o demo.i -nostdinc -P
-E 表示只进行预编译, -nostdinc will bypass standard #include files 。
1.1.2. 编译
可以使用下面的命令生成 .s 文件
gcc -S demo.c -o demo.s
1.1.3. 汇编
汇编的结果是产生目标文件,在 GCC 下的后缀为.o
1.1.4. 链接
目标文件已经是二进制文件,与可执行文件的组织形式类似,只是有些函数和全局变量的地址还未找到,程序不能执行。链接的作用就是找到这些目标地址,将所有的目标文件组织成一个可以执行的二进制文件。
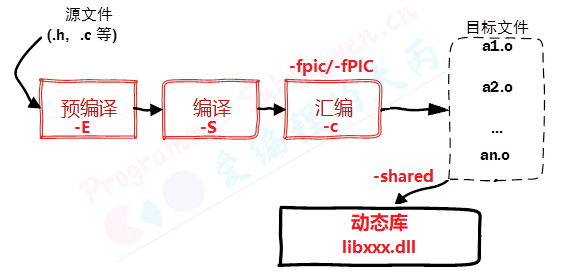
1.2. 动态链接库 1
生成动态链接库是直接使用gcc命令并且需要添加-fPIC(-fpic) 以及-shared 参数
- fPIC 或 -fpic 参数的作用是使得 gcc 生成的代码是与位置无关的,也就是使用相对位置。
- shared参数的作用是告诉编译器生成一个动态链接库。
2. 类型
2.1. 整数类型
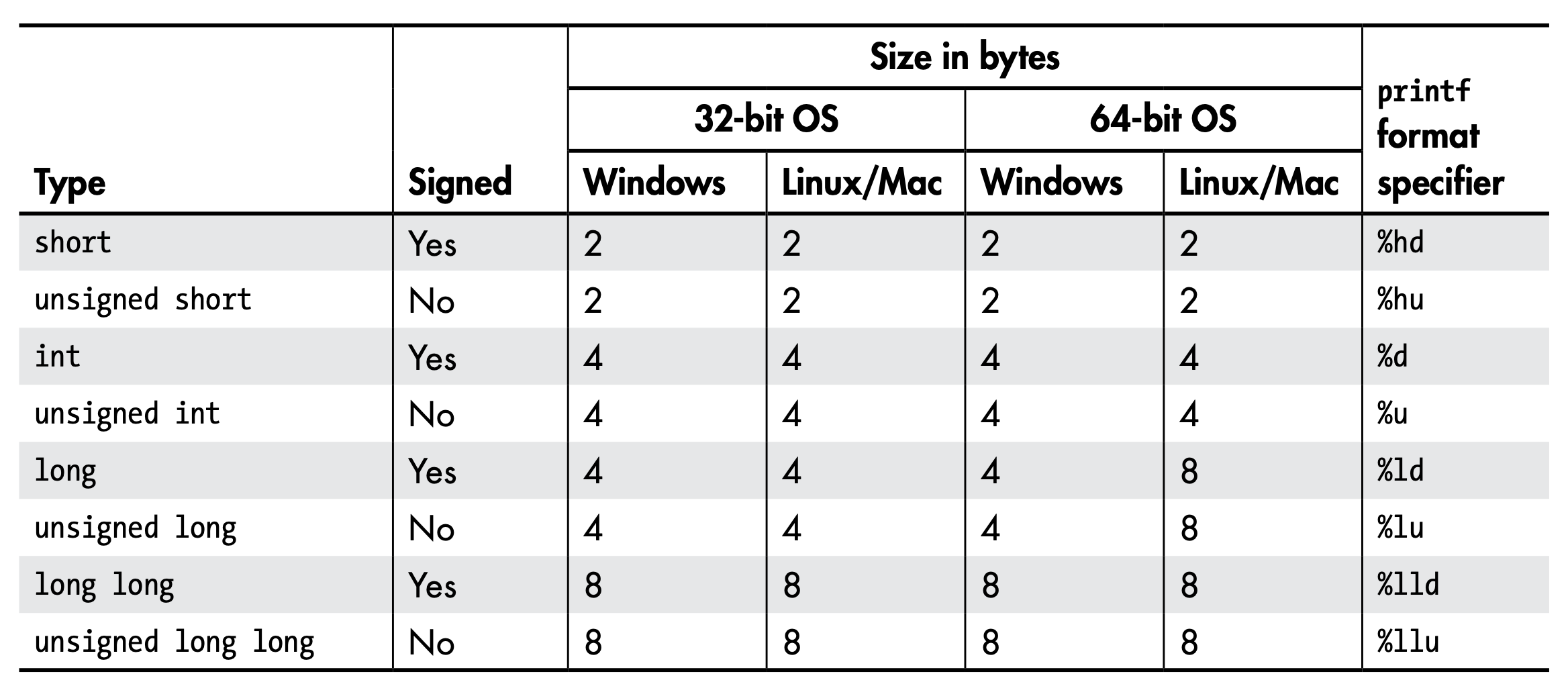
Figure 3: Integer Types, Sizes, and Format Specifiers
2.1.1. size_t
通常用 unsigned long long 实作,并用 %zd (十进制) 或 %zx(十六进制) 作为格式描述符。
2.2. 枚举类型
enum class Race { Dinan, Teklan, Ivyn, Moiran, Camite, Julian, Aidan }; Race langobard_race = Race::Aidan;
2.3. POD
尽量在 POD 中以 从大到小 排列成员。
2.4. 初始化
2.4.1. 基本类型初始化为零
int a = 0; int b{}; int c = {}; int d = { 0 }; int e; // 不要使用这种方式
2.4.2. 基本类型初始化为任意值
int e = 42; int f{ 42 }; int g = { 42 }; int h( 42 );
2.4.3. 数组初始化
int array_1[]{ 1, 2, 3 }; // array of 3 integers int array_2[5]{}; // array of 5 integers, all elements are initialized to 0 int array_3[5]{ 1, 2, 3 }; // array of 5 integers, first 3 elements are 1, 2, 3, the rest are 0 int array_4[5]; // array of 5 uninitialized integers (dangerous!)
2.4.4. POD 初始化
#include <cstdint> struct Pod { uint64_t a; char b[256]; bool c; }; int main() { Pod pod1{}; // all fields are zeroed Pod pod2 = {}; // all fields are zeroed Pod pod3{ 42, "hello" }; // a = 42, b = "hello", c = 0 Pod pod4{ 42, "hello", true }; // a = 42, b = "hello", c = true Pod pod5 = { 42, "hello", true }; // same as above Pod pod6 = { .a = 42, .b = "hello", .c = true }; // same as above }
2.4.5. 类初始化
struct Taxonomist { Taxonomist() { printf("(no argument)\n"); } Taxonomist(int x) { printf("int: %d\n", x); } Taxonomist(char x) { printf("char: %c\n", x); } Taxonomist(float x) { printf("float: %f\n", x); } }; int main() { Taxonomist t1; // (no argument) Taxonomist t2{ 'c' }; // char: c Taxonomist t3{ 65537 }; // int: 65537 Taxonomist t4 { 6.02e23f }; // float: 602000000000000000000000 Taxonomist t5('g'); // char: g Taxonomist t6 = { 'l' }; // char: l Taxonomist t7{}; // (no argument) Taxonomist t8(); // WRONG, 这是个函数声明,这就是要引入大括号初始化语法的一个主要原因,另一个主要原因是 Narrowing conversion }
2.4.6. 类成员初始化
不能使用小括号来初始化成员变量。
struct JohanVanDerSmut { bool gold = true; // equal sign int year_of_smelting_accident { 1970 }; // curly braces char key_location[8] = { "x-rated" }; // equal sign with curly braces };
2.4.7. Narrowing Conversion
每当发生 Implicit Narrowing Conversions 时,大括号初始化会产生告警, 这可以帮助减少 bug 。
float a{ 1 }; float b{ 2 }; int narrowed(a / b); // narrowing conversion printf("narrowed: %d\n", narrowed); int result { a / b }; // Compiler generated warning printf("result: %d\n", result);
2.5. 类型转换函数
2.5.1. const_cast
const int& const_val = 10; auto& val = const_cast<int&>(const_val); val = 20; log_info("const_val: %d, val: %d", const_val, val); // const_val: 20, val: 20
也可以使用 const_cast 从对象中去除 volatile 修饰符。
2.5.2. static_cast
short s = 600; void *target = &s; auto as_short = static_cast<short *>(target); log_info("as_short: %d", *as_short); // 600 float f = 3.14; auto as_int = static_cast<int *>(&f); // static_cast from 'float *' to 'int *' is not allowed
2.5.3. reinterpret_cast
通常用于 cast 两个完全不搭界的类型,使用者必须自行负责转换的正确性。
auto timer = reinterpret_cast<const uint64_t*>(0x7e00); printf("Time: %llu\n", *timer); // Segment fault
3. 对象
3.1. 拷贝语义
3.1.1. 拷贝构造
DerivedClass(const DerivedClass& other) : BaseClass(other) { // Copy constructor code }
通常当将值传递到某个函数中时,便会调用复制构造函数。
3.1.2. 拷贝赋值
DerivedClass& operator=(const DerivedClass& other) { if (this != &other) { // Copy the base class part BaseClass::operator=(other); // Copy the derived class part derivedMember = other.derivedMember; } return *this; }
拷贝赋值和拷贝构造的主要区别在于,在拷贝赋值中, 旧值可能已经有了一个值,必须在赋新值前,清理旧值的资源。
3.2. 移动语义
3.2.1. 移动构造
DerivedClass(DerivedClass&& other) noexcept : BaseClass(std::move(other)) { // move other's resources to this }
移动构造和拷贝构造类似 ,区别在于前者采用了右值引用而非左值引用。如果不加上 noexcept ,编译期会退而使用拷贝构造函数。
3.2.2. 移动赋值
DerivedClass& operator=(DerivedClass&& other) noexcept { if (this == &other) { return *this; } BaseClass::operator=(std::move(other)); // move other's members to this return *this; }
除了自引用检查和旧值清理逻辑之外,移动赋值的逻辑和移动构造的逻辑是相同的。
3.3. 编译器生成的方法
有五种方法与对象的内存控制相关:
- 析构函数
- 拷贝构造
- 移动构造
- 拷贝赋值
- 移动赋值
- 如果什么方法都不定制,编译器为这五个方法自动生成默认实现
- 拷贝构造和拷贝赋值的默认实现是在类的每个成员上调用拷贝构造或拷贝赋值运算符
- 如果定义了析构函数,拷贝构造,或拷贝复制这三个方法的任何一个,就会得到所有这三个函数的实现
- 如果只定义移动语义相关的方法,编译器会自动提供默认析构函数

Figure 4: A chart illustrating which methods the compiler generates when given various inputs
4. 多态
4.1. 接口 (运行时多态)
4.2. Template (编译期多态)
4.2.1. 分类
4.2.1.1. 函数模版
函数模板允许编写通用的函数,通过类型参数化,使其能够处理不同的数据类型。
#include <iostream> template <typename T> T maxValue(T a, T b) { return (a > b) ? a : b; } int main() { std::cout << maxValue(3, 7) << std::endl; // int 类型 std::cout << maxValue(3.14, 2.72) << std::endl; // double 类型 std::cout << maxValue('a', 'z') << std::endl; // char 类型 return 0; }
4.2.1.2. 类模板
类模板允许定义通用的类,通过类型参数化,实现不同类型的对象。
template <typename T>
class ClassName {
public:
T memberVariable;
};
4.2.1.3. 类型定义(Alias)模版
template <typename T> using List = std::list<T>; ContainerPrinter<int, List> lp; // type alias 使得 List 变成只需一个模版参数的模版类 const std::list l = {1, 2, 3, 4, 5}; const auto count = lp.Print(l); ASSERT_THAT(5 == count, "Expected 5 elements in the list");
4.2.2. 模版参数类型
4.2.2.1. 类型参数
template <typename T>
class MyClass {
public:
T data;
};
4.2.2.2. 非类型模版参数
// 在 C++ 中,数组类型包含了其大小信息,编译器可以通过模板参数推导自动推断出数组的长度 Length, // Index 需要显式指定 // 这种技术叫做非类型模板参数推导,让编译器能够从数组类型中提取大小信息,实现类型安全的数组访问 template <size_t Index, typename T, size_t Length> T& get(T (&arr)[Length]) { static_assert(Index < Length, "Index out of bounds"); return arr[Index]; } int arr[] = {1, 2, 3, 4, 5}; std::cout << get<2>(arr) << std::endl; // 3
4.2.2.3. 模版模版参数
模板模板参数允许模板接受另一个模板作为参数。这对于 封装容器 和策略模式等场景非常有用。
// 声明 Container 是一个模板类,且它只有"只有一个"模板参数 template <typename T, template <typename/*这里省略了名字(这里只是用于声明,也可以加上名字,比如U,但是没有实际意义)*/> class Container> // this is a template template parameter class ContainerPrinter { public: int Print(Container<T> c) { // NOLINT log_info("Printing container [%s] (%d elements) ...", typeid(Container<T>).name(), c.size()); for (const auto &item : c) { std::cout << item << " "; } std::cout << std::endl; return c.size(); } }; template <typename T, class Sequence = std::deque<T>> // this is NOT a template template parameter class SequencePrinter { public: int Print(Sequence s) { log_info("Printing sequence [%s] (%d elements) ...", typeid(Sequence).name(), s.size()); for (const auto &item : s) { std::cout << item << " "; } std::cout << std::endl; return s.size(); } }; const std::vector v = {1, 2, 3, 4, 5}; // 第二个模版参数无需指定模版参数类型,因为编译器会自动推导出 std::vector<int> 的类型 ContainerPrinter<int, std::vector> containerPrinter; const auto count = containerPrinter.Print(v); ASSERT_THAT(5 == count, "Expected 5 elements in the vector"); // SequencePrinter 并没有使用模版模版参数 SequencePrinter<int> s; // 第二个模版参数使用默认值 SequencePrinter<int, std::vector<int>> s2; // 第二个模版参数需要手工指定需要的参数类型 const std::deque d = {5, 6, 7, 8, 9, 10}; ASSERT_THAT(6 == s.Print(d), "Expected 6 elements in the deque"); ASSERT_THAT(5 == s2.Print(v), "Expected 5 elements in the vector");
4.2.3. 模版特化(Template Specialization)
模板特化允许为特定类型或类型组合提供专门的实现。
当通用模板无法满足特定需求时,特化模板可以调整行为以处理特定的情况。
C++ 支持 全特化(Full Specialization) 和 偏特化(Partial Specialization) ,但需要注意的是, 函数模板不支持偏特化,只能进行全特化。
不管是全特化还是偏特化,原始模版(主模版)是必须要写的。
全特化和偏特化都是对已存在的原始模板的"特殊化",没有原始模板就无法进行特化,而且 模版参数默认值只在主模板中有效,特化版本继承未特化参数的默认值 。
编译器的匹配顺序:
- 最匹配的特化版本(偏特化或全特化)
- 原始模板
只要类名或函数名后跟 <> , 就是特化版本, 就必须要有原始模版。原始模版类名或函数名后 不跟 <> .
主模版不一定要写实现体,可以先只写声明,通过特化提供实现,这是一种编译期条件分发技术。
4.2.3.1. 全特化
- 定义:为模板的所有参数提供具体类型
- 语法:以 template<> 开始, 后跟的类或函数必须再<>中明确使用的类型, 不会再出现模板参数(泛型符号)
- 作用:为特定类型组合提供完全不同的实现
类全特化:
// 原始模板 template<typename T, typename U> class MyClass { // 通用实现 }; // 全特化 template<> class MyClass<int, double> { // 需要用<>指定所有特化的泛型符号> // 专门为 int, double 的实现 };
函数全特化:
template<typename T, typename U> void func(T t, U u) { } // 全特化 template<> void func<int, int>(int t, int u) { }
4.2.3.2. 偏特化
- 定义:只为部分模板参数提供具体类型,其他参数仍为模板参数
- 语法:template<…> 中仍有模板参数(泛型符号)
- 作用:为某些参数模式提供特殊实现
// 原始模板 template<typename T, typename U> class MyClass { // 通用实现 }; // 偏特化 - 第二个参数固定为 int template<typename T> class MyClass<T, int> { // T 仍是模板参数,第二个参数固定为 int }; // 偏特化 - 指针类型 template<typename T> // 这行只不过是声明用到了哪些模版参数 class MyClass<T*, T*> { // 真正的"特化形式"定义其实是这行 // 专门处理指针类型 };
函数模板不支持偏特化主要有以下原因:
语言设计决策
C++标准委员会认为函数重载已经能很好地处理函数的"偏特化"需求,没必要引入额外的复杂性。
重载解析的复杂性
函数的偏特化会让模板匹配规则变得极其复杂,增加编译器实现难度和编译时间。
函数重载 + 全特化的组合已经能满足绝大多数需求,引入偏特化会带来更多复杂性而收益有限。
函数全特化在概念上是重载的一种形式,但在实现机制上是不同的系统。如果函数全特化和重载形式一样,且同时存在,重载的优先级更高。
template<typename T, typename U> void func(T t, U u) {} template<typename T> void func(T t, int u) {} // 这实际上是重载,不是偏特化 // 如果支持偏特化,应该这么写: // template<typename T> // void func<T, int>(T t, int u) {}
4.2.4. 变参模板(Variadic Templates)2
template <typename... Args>
class MyClass {
// 处理参数包
};
template <typename... Args>
void func(Args&... args) {
// 处理参数包
}
语法特点:
- 使用
...操作符定义参数包(parameter pack) - 通过递归或折叠表达式展开参数包
核心特点:
- 类型安全
- 编译时确定所有参数类型,避免运行时错误
- 零开销
- 编译期展开,无运行时性能损失
- 任意数量参数
- 可接受0到任意多个参数
- 完美转发
- 配合
std::forward保持参数的值类别
应用场景:
- 函数参数转发 (如
std::make_unique) - 容器构造函数
- 元编程和模板元函数
- 日志系统等需要灵活参数的场景
- 实现诸如
std::tuple,std::variant等模板库组件的基础
类变参模版有时需要结合模版特化,参见 https://github.com/ruanhao/cpp-for-fun/blob/dccb18b98be3e28b222120016cfc0127b59f5eed/src/test_template.cpp#L214 函数变参模版通常不需要利用特化,因为函数模版不支持偏特化。
4.2.4.1. 通过递归展开
template<typename T> void print(T&& t) { std::cout << t << std::endl; } template<typename T, typename... Args> void print(T&& t, Args&&... args) { std::cout << t << " "; print(args...); }
4.2.4.2. 通过折叠表达式展开
template<typename... Args> void print(Args&&... args) { ((std::cout << args << " "), ...); }
4.2.5. 模版折叠(c++17)
语法:
// 假设对于参数包 a, b, c, d (pack op ...) // 点点在右 → 右折叠 → 右结合: (a + (b + (c + d))) (... op pack) // 点点在左 → 左折叠 → 左结合: (((a + b) + c) + d) // 二元折叠 (pack op ... op init) // 初值在右 → 右折叠带初值 (init op ... op pack) // 初值在左 → 左折叠带初值
常见技巧:
- 逗号操作符最常用,适合执行副作用操作
- 逻辑操作符有短路特性,效率更高
- 算术操作注意空包情况,通常需要初值
- 累积操作使用左折叠更自然 [(… + args)]
- 执行操作使用右折叠更常见 [(func(args), …)]
- 利用 auto/decltype 可使函数返回值设计更简洁
这个写法很有意思:
// 检查所有类型是否相同 template<typename T, typename... Args> constexpr bool all_same_type_v = (std::is_same_v<T, Args> && ...); static_assert(all_same_type_v<int, int, int, int>, "Should be true for all same types"); static_assert(!all_same_type_v<double, int, int, int>, "Should be false for different types");
下面的代码 不是折叠表达式 ,而是 参数包展开(pack expansion):
std::vector<std::string> args_vec = {to_string(std::forward<Args>(args))...};
4.2.6. SFINAE (Substitution Failure Is Not An Error)
当编译器在模板实例化过程中进行类型替换时,如果替换失败,编译器不会报错,而是简单地从候选函数集合中移除该模板,继续尝试其他重载。
#include <type_traits> // 只对整数类型有效的函数 template<typename T> typename std::enable_if<std::is_integral<T>::value, void>::type process(T value) { std::cout << "Processing integer: " << value << std::endl; } // 使用 if constexpr 和 std::enable_if_t (C++17) template<typename T> std::enable_if_t<std::is_arithmetic_v<T>, bool> is_positive(T value) { return value > 0; } // 或者使用 requires 子句 (C++20) template<typename T> requires std::is_arithmetic_v<T> bool is_positive_v2(T value) { return value > 0; }
SFINAE 主要用于:
- 条件性启用/禁用模板函数
- 类型特征检测
- 重载决议控制
- 实现类型安全的泛型代码
SFINAE 常与模版参数默认值结合使用,以控制模板的启用条件:
template<typename T, typename = std::enable_if_t<std::is_integral_v<T>>> void process(T value) { // 只对整数类型启用 }
Concept 本质上是 SFINAE 的语法糖和增强版本:
- C++20 之前:使用 SFINAE
- C++20 及以后:优先使用 Concept
- Concept 提供更好的编译错误信息和代码可读性
decltype 也可以实现 SFINAE 。参见这里
5. 语法
5.1. 命名空间
5.1.1. using
using 会 ① 将符号导入块中,② 如果在命名空间中使用 using ,则会将符号导入当前命名空间。
namespace BroopKidron13::Shaltanc { enum class Color { Mauve, Pink, Russet } } int main() { using namespace BroopKidron13::Shaltanc::Color; const auto shaltanac_grass = Color::Russet; if (shaltanac_grass == Color::Russet) { printf("The grass is russet\n"); } }
5.1.2. constexpr if
constexpr if 主要用途是根据类型参数的某些属性在函数模版中提供自定义行为。 在运行期间,constexpr if 语句消失。
这个语句可以取代预处理器宏。
#include <cstdio> #include <stdexcept> #include <type_traits> template <typename T> auto value_of(T x) { if constexpr(std::is_pointer<T>::value) { if(!x) throw std::runtime_error{ "Null pointer dereference." }; return *x; } else { return x; } } int main() { unsigned long level{ 8998 }; auto level_ptr = &level; auto& level_ref = level; printf("Power level = %lu\n", value_of(level_ptr)); ++*level_ptr; printf("Power level = %lu\n", value_of(level_ref)); ++level_ref; printf("It's over %lu!\n", value_of(level++)); try { level_ptr = nullptr; value_of(level_ptr); } catch(const std::exception& e) { printf("Exception: %s\n", e.what()); } }
6. 函数
6.1. volatile
不能在 volatile 对象上调用非 volatile 方法。
6.2. 可调用对象
6.2.1. 函数指针
static void _print(int age, std::string name) { log_info("age=%d, name=%s", age, name.c_str()); } static void testCallableFuncPtr() { log_info("=== %s ===", __func__); using FuncPtr = void (*)(int, std::string); FuncPtr funcPtr = _print; funcPtr(30, "Paul"); }
6.2.2. 具有 operator() 成员函数的类对象
static void testCallableFunctor() { log_info("=== %s ===", __func__); struct Functor { void operator()(int age, std::string name) { log_info("age=%d, name=%s", age, name.c_str()); } }; Functor functor; functor(30, "Paul"); // 使用 std::function 包装可调用对象 std::function<void(int, std::string)> func = functor; func(26, "Ryan"); }
6.2.3. 可转换为函数指针的类对象
static void testCallableClassFuncPtr() { log_info("=== %s ===", __func__); using FuncPtr = void (*)(int, std::string); struct MyClass { operator FuncPtr() { return _print; } static void _print(int age, std::string name) { log_info("[MyClass::_print] age=%d, name=%s", age, name.c_str()); } }; MyClass myClass; myClass(30, "Paul"); std::function<void(int, std::string)> func = myClass; // 使用 std::function 包装可调用对象 func(26, "Ryan"); }
6.2.4. 类成员函数指针或类成员变量指针
这种类型的可调用对象,需要借助 binder 才能转换成 std::function
static void testCallableClassMemberFuncPtr() { log_info("=== %s ===", __func__); struct MyClass { void print(int age, std::string name) { log_info("[%p::print] age=%d, name=%s", this, age, name.c_str()); } }; using FuncPtr = void (MyClass::*)(int, std::string); MyClass myObj; log_info("myObj=%p", &myObj); FuncPtr funcPtr = &MyClass::print; (myObj.*funcPtr)(30, "Paul"); // 使用 std::function 包装可调用对象 std::function<void(int, std::string)> func = std::bind(funcPtr, &myObj, std::placeholders::_1, std::placeholders::_2); func(26, "Ryan"); }
static void testCallableClassMemberPtr() { log_info("=== %s ===", __func__); struct MyClass { MyClass() : value(10) {} int value; }; using Ptr = int MyClass::*; MyClass myObj; log_info("myObj=%p", &myObj); Ptr ptr = &MyClass::value; log_info("myObj.*ptr=%d", myObj.*ptr); myObj.*Ptr(&MyClass::value) = 20; // way 1 log_info("myObj.*ptr=%d", myObj.*ptr); myObj.*ptr = 30; // way 2 log_info("myObj.*ptr=%d", myObj.*ptr); // 使用 std::function 包装可调用对象 std::function<int(MyClass&)> func = std::bind(ptr, std::placeholders::_1); log_info("func(myObj)=%d", func(myObj)); }
6.3. binder
std::bind 用来将可调用对象与其参数一起进行绑定。绑定后的结果可以使用 std::function 进行保存,
并延迟到需要的时候调用。主要有两大作用:
- 将可调用对象与其参数一起绑定成一个 仿函数
- 将多元(参数个数为n,n>1)可调用对象转换为一元或者(n-1)元可调用对象,即绑定部分参数
绑定器函数使用语法格式如下:
// 绑定非类成员函数/变量 auto f = std::bind(可调用对象地址, 绑定的参数/占位符); // 绑定类成员函/变量 auto f = std::bind(类函数地址/成员地址(其实是偏移量), 类实例对象地址, 绑定的参数/占位符);
7. 智能指针

Figure 5: Smart Pointers in stdlib and Boost
8. 迭代器
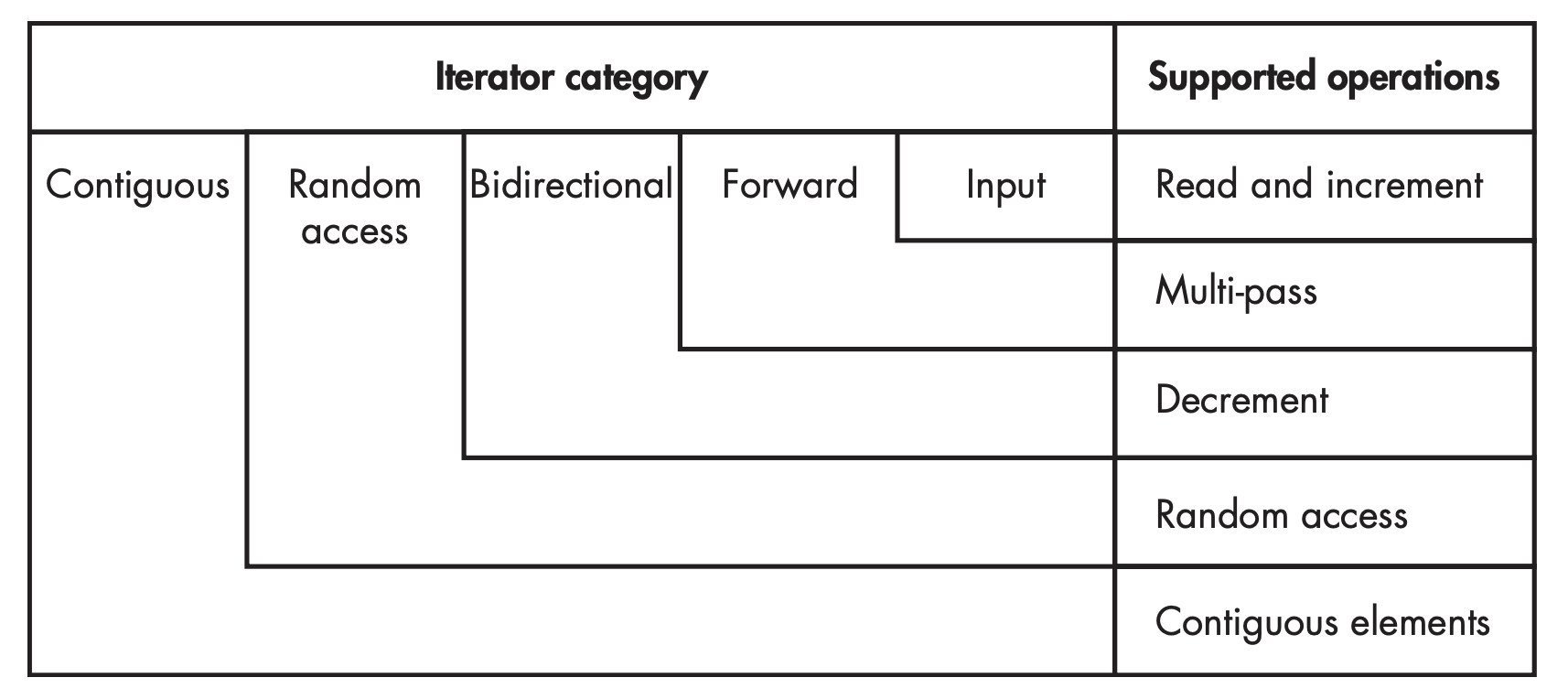
Figure 6: Iterator categories and their nested relationships
9. 并发编程
9.1. async/future/promise
9.1.1. async 启动策略
std::async 函数可以接受几个不同的启动策略,除了 std::launch::async 之外,还有以下启动策略:
std::launch::deferred这种策略意味着任务将在调用
std::future::get()或std::future::wait()函数时延迟执行。换句话说,任务将在需要结果时同步执行。std::launch::async | std::launch::deferred这种策略是上面两个策略的组合。任务可以在一个单独的线程上异步执行,也可以延迟执行,具体取决于实现(比如参考当前 CPU 负载)。
默认情况下, , std::async 使用 std::launch::async | std::launch::deferred 策略。这意味着任务可能异步执行,也可能延迟执行,具体取决于实现。
9.1.2. future 等待
std::future::get()
阻塞调用,用于获取 std::future 对象表示的值或异常。如果异步任务还没有完成, get() 会阻塞当前线程,直到任务完成。如果任务已经完成, get() 会立即返回任务的结果。 重要的是,get() 只能调用一次, 因为它会移动或消耗掉 std::future 对象的状态。一旦 get() 被调用, std::future 对象就不能再被用来获取结果。
std::future::wait()
阻塞调用,与 get() 的主要区别在于 wait() 不会返回任务的结果,只是等待异步任务完成。 wait() 可以被多次调用,不会消耗 std::future 对象的状态。
9.1.3. packaged_task
std::packaged_task 是一个可调用目标,它包装了一个任务,该任务可以在另一个线程上运行。可以捕获任务的返回值或异常,并将其存储在 std::future 对象中,以便以后使用。
// 创建 packaged_task std::packaged_task task([] {return calc_string_len("hello");}); // 获取与任务关联的 std::future 对象 std::future<decltype(calc_string_len(""))> result = task.get_future(); ASSERT_THAT(result.valid(), "Should be valid"); // 在另一个线程上执行任务 std::thread t(std::move(task)); t.detach(); // 分离线程 // 等待任务完成并获取结果 const size_t value = result.get(); ASSERT_THAT(5 == value, "result should be 5"); ASSERT_THAT(!result.valid(), "Not valid");
9.1.4. promise
// 创建一个 promise 对象 std::promise<int> p; // 获取与 promise 关联的 future 对象 std::future<int> f = p.get_future(); // 在另一个线程上设置 promise 的值 std::thread t(set_value, std::move(p)); t.join(); // 等待 future 完成并获取结果 const int value = f.get(); ASSERT_THAT(value == 42, "value should be 42");
10. Memory Order 3 , 4 , 5
Memory Order 控制了执行结果在多核中的可见顺序,这个可见顺序与代码序不一定一致:
- 原因一是 汇编指令优化重排
- 原因二是 CPU 实际执行时乱序执行 以及 部分 CPU 架构上没有做到内存强一致性 (内存强一致性:执行结果出现的顺序应该和指令顺序一样,不存在重排乱序) ,导致后面的代码执行完成的时候,前面的代码修改的内存却还没改变
在可能出现问题的场景下,需要手动干预以避免问题,汇编(软件)和 CPU(硬件) 都提供了相应的指令取进行干预控制,C++ 的 atomic中的 Memory Order 可以看成是这些控制的 封装 ,隐藏了底层,之所以有六种是因为这种控制是有代价,从松散到严格开销越来越高,在某些场景下,是允许部分重排的,只是对于小部分重排会导致问题的才需要加以控制,那么只需要衉一些低开销的控制即可。
Memory Order 的作用是:
- 干预汇编重排
- 干预硬件乱序执行
- 控制执行结果在多核间的可见性
可以说,Memory Order 是用来限制编译器以及 CPU 对单线程当中的指令执行顺序进行重排的 程度 (此外还包括对 cache 的控制方法)。
这种限制,决定了以 atomic 操作为基准点(边界),对其之前后的内存访问命令,能够在多大的范围内自由重排, 也被称为栅栏 。
六种模型参数本质上是限制单线程内部的指令重排顺序, 并不是同步不同线程之间的指令顺序 。
通过不同的参数选择,来控制带有模型参数的变量前后的指令被重排顺序的程度。
10.1. 硬件内存模型
随着 CPU 的不断发展,CPU 的计算能力远超过从主存 (DRAM) 中读写速度。为了提升数据读写速度,慢慢的加入了 Cache, Store Buffer, Invalidate Queue 等硬件,并允许 CPU 的乱序执行:
实际的 CPU 在运行指令过程中并非表现得一条执行完了才执行下一条指令,比如一个 MOV 指令会导致 CPU 的 Load Unit 忙而 ALU (逻辑计算单元) 空闲,因此在等取值的同时,预先做下一个能够做的计算指令,这样的乱序执行提升了CPU 的使用率。
Store Buffer, Invalidate Queue 的出现带来了不同的内存一致性模型,从而导致执行结果在多核下的可见顺序不同,所以在编程时需考虑这点,以下总结了常见的四种内存一致性模型以及它们对执行结果的在多核中可见顺序的影响。
10.1.1. 顺序存储模型(SC: Sequential Consistency)
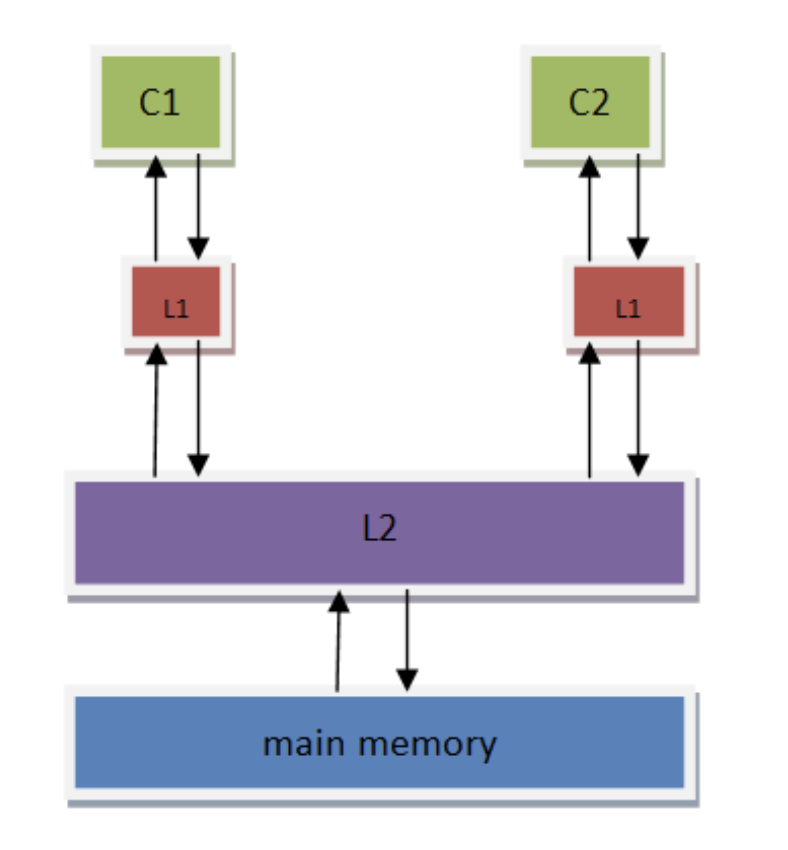
Figure 7: 顺序存储模型
多核 cache 间使用 MESI 协议进行数据同步,不存在数据一致性问题,因此在这种模型下,多线程程序的运行与所期望的执行情况是一致的, 不会出现内存访问乱序的情况。
顺序存储模型是最简单的存储模型,也称为 强定序模型 。CPU 会按照代码来执行所有的 load 与 store 动作,即按照它们在程序的顺序流中出现的次序来执行。从主存储器和 CPU 的角度来看,load 和 store 是顺序地对主存储器进行访问。
可以把顺序存储模型想象成单核系统。
10.1.2. 存储定序模型
10.1.2.1. 完全存储定序(TSO: Total Store Order)【引发 store-load 乱序】
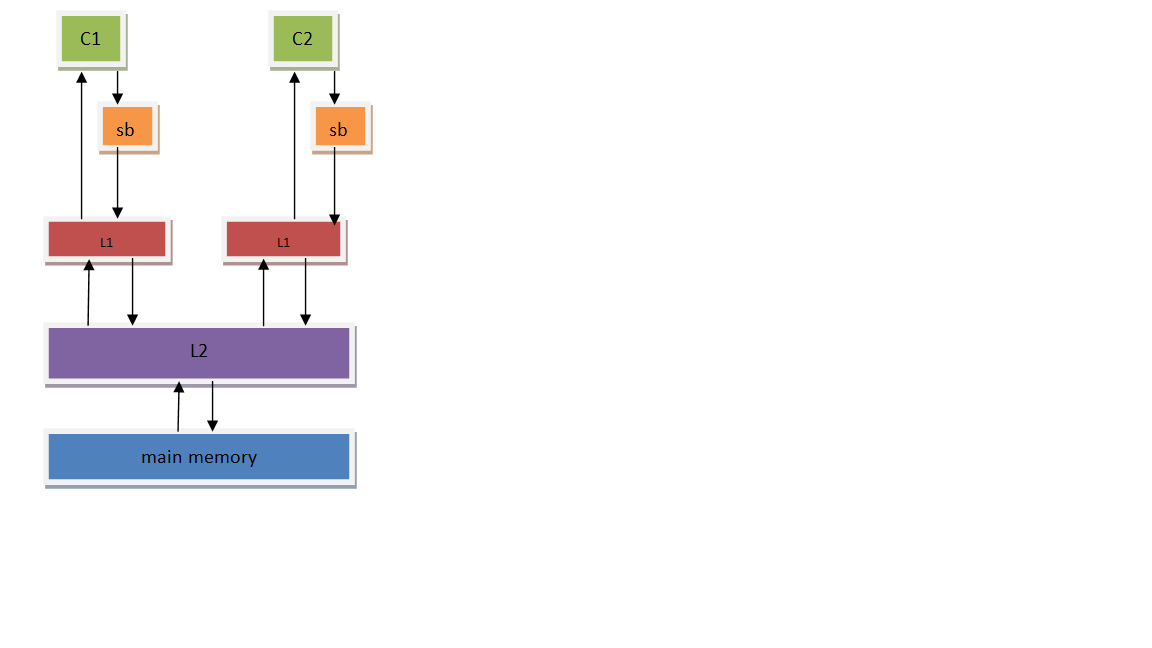
Figure 8: Total Store Order (TSO)
为了提高 CPU 的性能,芯片设计人员在 CPU 中包含了一个存储缓存区(store buffer),它的作用是为 store 指令提供缓冲,使得CPU不用等待存储器的响应。所以对于写而言,只要 store buffer 里还有空间,写就只需要1个时钟周期,所以 store buffer 的存在可以很好的减少写开销。
Store Buffer 必须严格按照 FIFO 的次序将数据发送到主存(所谓的FIFO表示先进入store buffer的指令数据必须先于后面的指令数据写到存储器中),CPU 必须要严格保证 store buffer 的顺序执行,这种内存模型就叫做完全存储定序(TSO)。x86 CPU 就是这种内存模型。
相比于以前的内存模型而言,store 的时候数据会先被放到store buffer里面,然后再被写到L1 cache里。 因此这引入了访问乱序的根源 :因为 store 操作会放入 SB ,而 load 操作直接被 CPU 执行,产生了两条执行路径,因这种原因产生的乱序称之为 store-load 乱序 。
10.1.2.2. 部分存储定序(PSO: Part Store Order)【引发 store-store 乱序】
TSO 在有 store buffer 的情况下已经带来了不小的性能提升,但是芯片设计人员并不满足于这一点,于是在 TSO 模型的基础上继续放宽内存访问限制:允许 CPU 以非 FIFO 来处理 store buffer 缓冲区中的指令。 CPU 只需保证地址相关指令在store buffer中才会以FIFO的形式进行处理 ,即对 同一个相同的地址做store,才会有严格执行顺序制约 ,而其他的则可以乱序处理,这被称为部分存储定序(PSO) ,产生的乱序称为 store-store乱序 。
10.1.3. 宽松存储模型(RMO: Relax Memory Order) 【引入 load-load 和 load-store 乱序】
为了榨取更多的性能,在 PSO 的模型的基础上,更进一步的放宽了内存一致性模型,不仅允许 store-load,store-store 乱序,还进一步允许 load-load ,load-store 乱序, 只要是地址无关的指令 ,在读写访问的时候都可以打乱所有顺序,这就是宽松内存模型(RMO)。
这是一种乱序随处可见的内存一致性模型,ARM 的很多微架构就是使用 RMO 模型。
10.1.4. 干预工具
10.1.4.1. 内存屏障(memory barrier)
内存屏障的最根本的作用就是提供一个机制,要求CPU在这个时候必须以顺序存储一致性模型的方式来处理load与store指令,这样才不会出现内存访问不一致的情况。
内存屏障可以细分为:
write memory barrier 【也称 sfence (sotre fence) ,解决 store-load/store-store 问题】
将 store buffer 中的数据全部刷进 cache 。刷到 cache 这部分的数据被更新了,就会触发 cache 的 mesi 进行同步,发送 cacheline 的 invalidate message 告知其它 cache 持有的数据失效了,赶紧标注一下然后同步,然后其他的 core 会返回 invalidate ack 之后这时才会继续向下执行。
read memory barrier 【也称 lfence (load fence) ,解决 load-store/load-load 问题】
flush Invalidate Queue
full memory barrier
read memory barrier + write memory barrier
10.1.4.2. Invalidate Message Queue (针对 TSO)
使用 memory barrier 方式需要在 cacheline 上发送 message,一来一回需要等待时间,这对于 CPU 设计者来说同样是不可接受的。因此又引入了Invalidate Queue 。
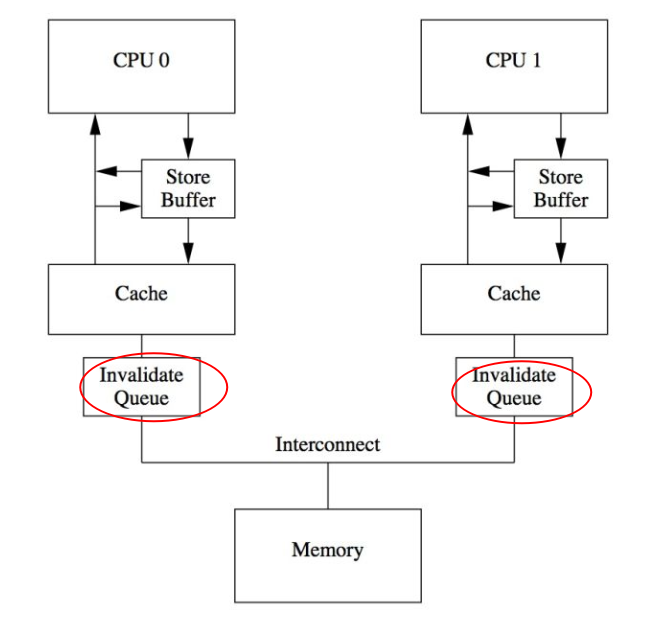
有了 Invalidate Queue 之后,发送的 Invalidate Message 只需要 push 到对应 core 的 Invalidate Queue 即可,然后这个core就会返回继续执行,中间不需要等待。这样cache之间的沟通就不会有很大的阻塞了。
在被通知的CPU上运行的线程其实也需要内存屏障(load fence) ,因为如果不及时处理 Invalidate Queue,那就仍然持有旧数据。
10.1.4.3. Lock 指令 【X86 平台】
Lock 不是一种内存屏障,但是它能完成类似内存屏障的功能。它会对CPU总线和高速缓存加锁,可以理解为CPU指令级的一种锁,实现了以下作用:
- 先对总线/缓存加锁,然后执行后面的指令。
- Lock 后的写操作会通过 cache 间的 MESI 协议让其他 CPU 相关的 cache line 失效。
- 最后释放锁后会把高速缓存中的脏数据全部刷新回主内存。
- 在锁住总线的时候,其他 CPU 的读写请求都会被阻塞,直到锁释放。
10.2. 软件内存模型语义
10.2.1. memory_order_seq_cst
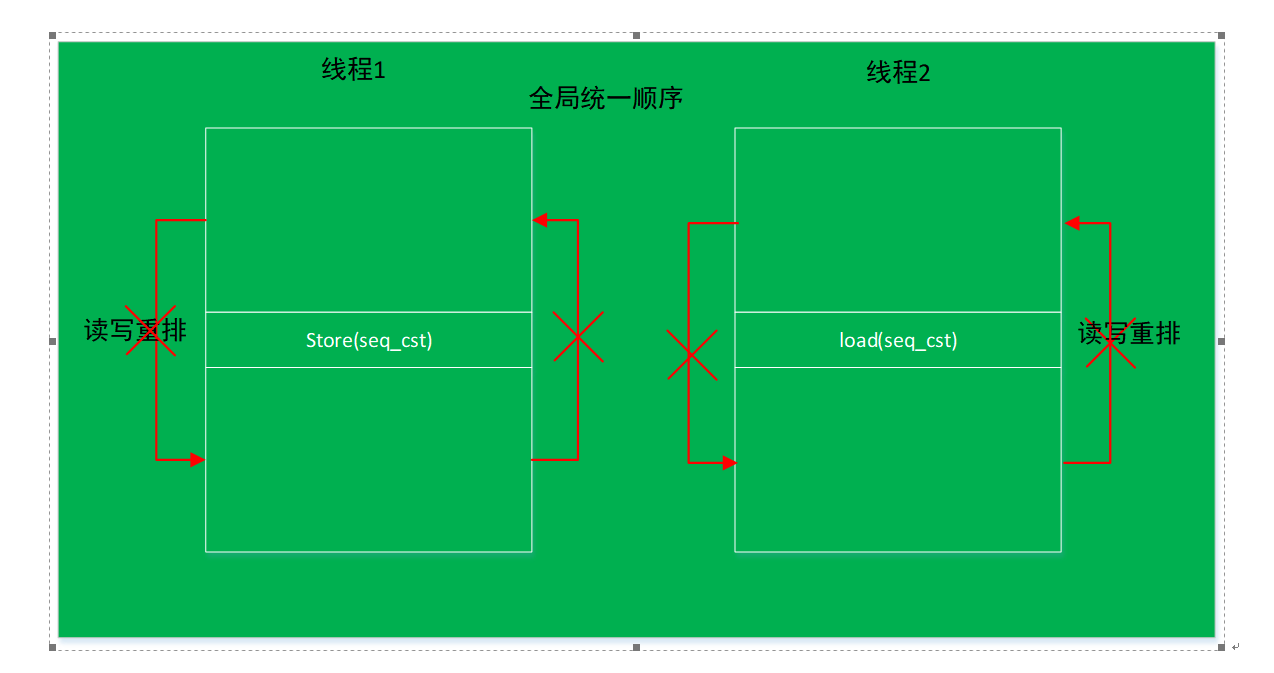
要求底层提供顺序一致性模型,如果程序的运行底层架构是非内存强一致模型,则使用cpu提供的内存屏障等操作保证强一致,同时要求代码进行编译的时候不能够做任何指令重排。
该模型可以解决一切问题。
10.2.2. memory_order_release/memory_order_acquire
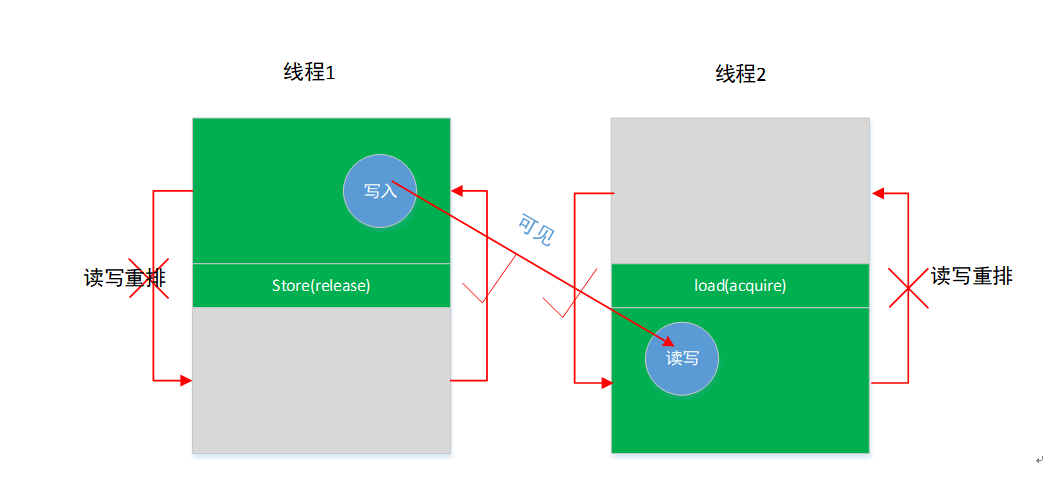
允许cpu或者编译器做一定的指令乱序重排,但是由于TSO,PSO的存在,可能产生的store-load/store-store乱序从而导致问题。那么涉及到多核交互的时候,就需要手动使用release, acquire去避免这样的问题。
与memory_order_seq_cst最大的不同的是,它是对具体代码可能出现的乱序做具体解决而不是要求全部都不能重排。
- load(acquire) 之后的所有写操作(包含非依赖关系),不允许被移动到这个 load(acquire) 的前面,一定在 load 之后执行。
- store(release) 之前的所有读写操作(包含非依赖关系),不允许被重排到这个 store(release) 的后面,一定在 store 之前执行。
- 如果 store(release) 在 load(acquire) 之前执行了,那么 store(release) 之前的写操作对 load(acquire) 之后的读写操作可见。
- 绿色区域的代码依然可以允许编译器或 CPU 为了优化目的重排序,但不能超越屏障。
10.2.3. memory_order_relaxed
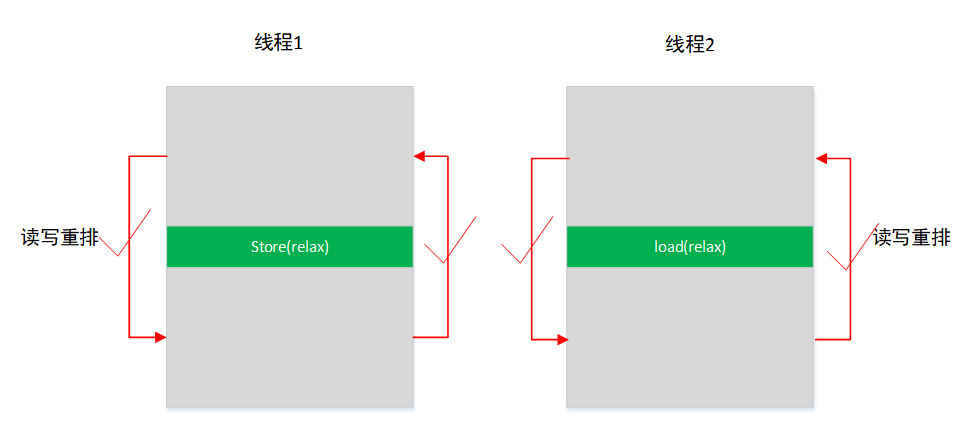
完全放开,让编译器和cpu自由搞,如果cpu是SC的话,cpu层不会出现乱序,但是编译层可能会做重排,结果也是无法保证的。
可用在代码上没有乱序要求的场景或者没有多核交互的情况下,以提升性能。
10.2.4. memory_order_acq_rel
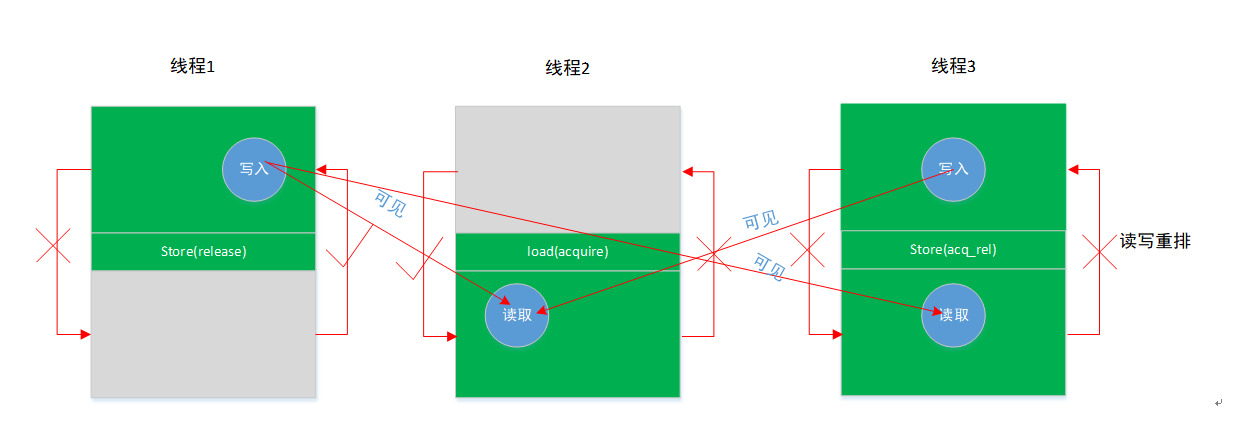
- 前面无法被重排到后面,后面无法被重排到前面。
- 可以看见其他线程施加 release 之前的所有写入,同时自己之前所有写入对其他施加 acquire 语义的线程可见。
11. C++11
11.1. auto
11.1.1. 限制
不能作为函数参数使用
int func(auto a, auto b) // error { cout << "a: " << a <<", b: " << b << endl; }
不能用于类的非静态成员变量的初始化
class Test { auto v1 = 0; // error static auto v2 = 0; // error,类的静态非常量成员不允许在类内部直接初始化 static const auto v3 = 10; // ok };
- 不能使用auto关键字定义数组
不能使用auto推导出模板参数
template <typename T> struct Test{} int func() { Test<double> t; Test<auto> t1 = t; // error, 无法推导出模板类型 return 0; }
11.1.2. 常见应用
- STL的容器遍历
泛型编程
#include <iostream> #include <string> using namespace std; class T1 { public: static int get() { return 10; } }; class T2 { public: static string get() { return "hello, world"; } }; template <class A> void func(void) { auto val = A::get(); cout << "val: " << val << endl; } int main() { func<T1>(); func<T2>(); return 0; }
11.2. decltype
它的作用是在编译器编译的时候推导出一个表达式的类型。
11.2.1. 推导普通变量或者普通表达式或者类表达式
#include <iostream> #include <string> using namespace std; class Test { public: string text; static const int value = 110; }; int main() { int x = 99; const int &y = x; decltype(x) a = x; // int decltype(y) b = x; // const int & decltype(Test::value) c = 0; // const int Test t; decltype(t.text) d = "hello, world"; // string cout << "a: " << typeid(a).name() << endl; cout << "b: " << typeid(b).name() << endl; cout << "c: " << typeid(c).name() << endl; cout << "d: " << typeid(d).name() << endl; return 0; }
11.2.2. 推导函数返回值
class Test{...}; //函数声明 int func_int(); // 返回值为 int int& func_int_r(); // 返回值为 int& int&& func_int_rr(); // 返回值为 int&& const int func_cint(); // 返回值为 const int const int& func_cint_r(); // 返回值为 const int& const int&& func_cint_rr(); // 返回值为 const int&& const Test func_ctest(); // 返回值为 const Test //decltype类型推导 int n = 100; decltype(func_int()) a = 0; // int decltype(func_int_r()) b = n; // int& decltype(func_int_rr()) c = 0; // int&& decltype(func_cint()) d = 0; // int decltype(func_cint_r()) e = n; // const int & decltype(func_cint_rr()) f = 0; // const int && decltype(func_ctest()) g = Test(); // const Test
11.2.3. 推导表达式类型的引用
表达式是一个左值,或者被括号( )包围,使用 decltype 推导出的是表达式类型的引用。
#include <iostream> #include <vector> using namespace std; class Test { public: int num; }; int main() { const Test obj; decltype(obj.num) a = 0; // int decltype((obj.num)) b = a; // const int & int n = 0, m = 0; decltype(n + m) c = 0; // int decltype(n = n + m) d = n; // int & return 0; }
11.3. using= 【类型别名】
类型别名可以出现在任何作用域:块,类,或者命名空间。(作用和 typedef 相同)
该技法还可以为模版定义类型别名(这是 typedef 无法做到的),用于减少 模版参数 :
#include <cstdio> #include <stdexcept> template <typename To, typename From> struct NarrowCaster { To cast(From value) const { const auto converted = static_cast<To>(value); const auto backwards = static_cast<From>(converted); if(value != backwards) throw std::runtime_error{ "Narrowed!" }; return converted; } }; template <typename From> using short_caster = NarrowCaster<short, From>; int main() { try { const short_caster<int> caster; const auto cyclic_short = caster.cast(142857); printf("cyclic_short: %d\n", cyclic_short); } catch(const std::runtime_error& e) { printf("Exception: %s\n", e.what()); } }
11.4. constexpr
在使用中建议将 const 和 constexpr 的功能区分开,即凡是表达"只读"语义的场景都使用 const,表达"常量"语义的场景都使用 constexpr。
11.4.1. 修饰普通函数/类成员函数
使用前提条件:
- 函数必须要有返回值,并且return 返回的表达式必须是常量表达式
- 函数在使用之前,必须有对应的定义语句,不能只看见声明
- 函数体中,不能出现非常量表达式之外的语句,但可以有 using 、typedef、static_assert 和 return
11.4.2. 修饰模板函数
由于模板中类型的不确定性, 如果 constexpr 修饰的模板函数实例化结果不满足常量表达式函数的要求(主要看对应类型的参数是否是一个右值),则 constexpr 会被自动忽略,相当于一个普通函数。
11.4.3. 修饰构造函数
常量构造函数有一个要求: 构造函数的函数体必须为空,并且必须采用初始化列表的方式为各个成员赋值。
11.5. 委托构造/继承构造
委托构造函数允许使用同一个类中的一个构造函数调用其它的构造函数,从而简化相关变量的初始化:
#include <iostream> using namespace std; class Test { public: Test() {}; Test(int max) { this->m_max = max > 0 ? max : 100; } Test(int max, int min):Test(max) { this->m_min = min > 0 && min < max ? min : 1; } Test(int max, int min, int mid):Test(max, min) { this->m_middle = mid < max && mid > min ? mid : 50; } int m_min; int m_max; int m_middle; }; int main() { Test t(90, 30, 60); cout << "min: " << t.m_min << ", middle: " << t.m_middle << ", max: " << t.m_max << endl; return 0; }
继承构造函数的使用方法是这样的:通过使用using 类名::构造函数名(其实类名和构造函数名是一样的)来声明使用基类的构造函数,这样子类中就可以不定义相同的构造函数了,直接使用基类的构造函数来构造派生类对象:
#include <iostream> #include <string> using namespace std; class Base { public: Base(int i) :m_i(i) {} Base(int i, double j) :m_i(i), m_j(j) {} Base(int i, double j, string k) :m_i(i), m_j(j), m_k(k) {} void func(int i) { cout << "base class: i = " << i << endl; } void func(int i, string str) { cout << "base class: i = " << i << ", str = " << str << endl; } int m_i; double m_j; string m_k; }; class Child : public Base { public: using Base::Base; // 继承构造 using Base::func; // 如果在子类中隐藏了父类中的同名函数,也可以通过using的方式在子类中使用基类中的这些父类函数 void func() { cout << "child class: i'am luffy!!!" << endl; } }; int main() { Child c(250); c.func(); c.func(19); c.func(19, "luffy"); return 0; }
11.6. 万能引用
template<typename T> void func(T&& x) { } int i = 0; func(1); func(i);
万能引用中,T 只能是 int&(左值)或 int(右值)
T = int&& 只能通过显式模板参数指定,但那样就失去了万能引用的意义。
template<typename T> static bool is_lvalue([[maybe_unused]] T&& x) { const std::string suffix = std::is_lvalue_reference_v<T> ? "&" : std::is_rvalue_reference_v<T> ? "&&" : ""; log_info("T: %s%s", typeid(T).name(), suffix.c_str()); return std::is_lvalue_reference_v<decltype(x)>; } template<typename T> static bool is_rvalue([[maybe_unused]] T&& x) { const std::string suffix = std::is_lvalue_reference_v<T> ? "&" : std::is_rvalue_reference_v<T> ? "&&" : ""; log_info("T: %s%s", typeid(T).name(), suffix.c_str()); // return std::is_rvalue_reference_v<decltype(x)>; return std::is_rvalue_reference_v<T&&>; // 这样写更巧妙, 利用了引用折叠概念 } String s1; const String s2; int &&i = 1; ASSERT_THAT(is_lvalue("hello"), "字符串字面量的类型是数组,而数组是左值,这是 C++ 的设计决定"); ASSERT_THAT(is_rvalue(String("hello")), "Should be rvalue"); ASSERT_THAT(is_lvalue(s1), "Should be lvalue"); ASSERT_THAT(is_rvalue(s1 + s2), "Should be rvalue"); ASSERT_THAT(is_rvalue(std::move(s1)), "Should be rvalue"); ASSERT_THAT(is_lvalue(s2), "Should be lvalue"); ASSERT_THAT(is_rvalue(1), "T: int, x: int&&, Should be rvalue"); ASSERT_THAT(is_rvalue<int&&>(1), "T: int&&, x: int&&, Should be rvalue"); // T 只有这样写才是右值引用, 但这种写法失去了使用万能引用的意义 // std::forward 就是要解决下面这个问题, 即如何通过万能引用来保持右值引用信息 ASSERT_THAT(is_lvalue(i), "T: int&, x: int&, 右值引用变量本身是左值"); ASSERT_THAT(is_rvalue(std::move(i)), "T: int, x: int&&, 右值引用变量 std::move(i) 是右值");
有个疑问, 为什么对于 void func(T&& x), std::forward 可以做到根据 x 的类型选择对应的特例模版进行实例化,而函数重载不行呢?难道"一旦进入函数体,x 就是一个具名参数,因此总是左值"这种说法仅是针对函数而言的? 而模版的参数推导其实是可以识别左值和右值的?
下面是 std::forward 的实现:
template <class _Tp> _LIBCPP_NODISCARD inline _LIBCPP_HIDE_FROM_ABI _LIBCPP_CONSTEXPR _Tp&& forward(_LIBCPP_LIFETIMEBOUND __libcpp_remove_reference_t<_Tp>& __t) _NOEXCEPT { return static_cast<_Tp&&>(__t); } template <class _Tp> _LIBCPP_NODISCARD inline _LIBCPP_HIDE_FROM_ABI _LIBCPP_CONSTEXPR _Tp&& forward(_LIBCPP_LIFETIMEBOUND __libcpp_remove_reference_t<_Tp>&& __t) _NOEXCEPT { static_assert(!is_lvalue_reference<_Tp>::value, "cannot forward an rvalue as an lvalue"); return static_cast<_Tp&&>(__t); }
AI 的回答:
- "一旦绑定到函数参数,右值就变成左值"是指在函数体内部访问这个参数时的行为 - 模板参数推导本身是可以在编译期区分左值引用和右值引用的 - std::forward<T>(x) 利用这个推导出的 T 来恢复原来的值类别 - 而函数重载是在实参已经退化为左值之后做的选择,因此无法"感知"原始值类别。
12. 设计思想
12.1. CRTP
将派生类作为模版参数传递给基类的技术 ,即一个类继承一个以自身为模版参数的基类。这种模式多用于实现静态多态,接口默认实现,以及编译时策略选择等。是虚函数的一种替代方法,项目中可以按需选择使用虚函数或是CRTP。
CRTP的缺点是无法做成基于接口的动态库来隐藏实现。
template <typename T>
class TempClass {
void execute(const std::string& args) {
// Call the implementation method of the derived class
static_cast<T*>(this)->executeImpl(args);
}
};
//CRTP
class RealClass: public TempClass<RealClass>{
void executeImpl(const std::string& args) {
// Implementation for RealClass
std::cout << "Executing in RealClass with args: " << args << std::endl;
}
};
12.3. 策略包装6
12.3.1. 虚函数
最简单直接的方式。
12.3.2. CRTP/std::function/lambda
使用 CRTP 效率高,std::function 和 labmbda 结合达到类型擦除的目的。
template <typename T>
class BaseCommand {
public:
void execute(const std::string& args) {
static_cast<T*>(this)->executeImpl(args);
}
};
class AddCommand : public BaseCommand<AddCommand> {
public:
static void executeImpl(const std::string& args) {
log_info("[%s] Add command", args.c_str());
}
};
class MinusCommand : public BaseCommand<MinusCommand> {
public:
static void executeImpl(const std::string& args){
log_info("[%s] Minus command", args.c_str());
}
};
auto add_command = std::make_shared<CRTPWay::AddCommand>();
auto minus_command = std::make_shared<CRTPWay::MinusCommand>();
std::unordered_map<std::string, std::function<void(const std::string&)> > commands;
commands.emplace("add", [add_command](const std::string& args) { add_command->execute(args); });
commands.emplace("minus", [minus_command](const std::string& args) { minus_command->execute(args); });
commands["add"]("by CRTP");
commands["minus"]("by CRTP");
12.3.3. variant
using CommandVariant = std::variant<CRTPWay::AddCommand, CRTPWay::MinusCommand>; std::unordered_map<std::string, CommandVariant> commands; commands["add"] = CRTPWay::AddCommand(); commands["minus"] = CRTPWay::MinusCommand(); std::string args = "by variant"; std::visit([&args](auto&& cmd) { cmd.execute(args); }, commands["add"]); std::visit([&args](auto&& cmd) { cmd.execute(args); }, commands["minus"]);
std::variant 是 C++17 引入的一个类型安全的联合体,能够持有预定义类型中的一种。
std::visit 是一个用于访问 std::variant 中当前存储的值的函数。它接受一个访问者(通常是一个函数或lambda)和一个std::variant。
使用 variant 的优点是:
- 类型安全: 与传统的基类指针相比,
std::variant在编译时就知道所有可能的类型,减少了运行时错误的风险。 - 性能:
std::variant通常比基类多态更高效,因为它避免了虚函数调用的开销。 - 简洁性: 使用
std::variant和std::visit可以避免复杂的类型检查和转换逻辑,使代码更简洁和易于维护。
通常用于需要在运行时存储和管理多种不同类型对象的场景,同时保持类型安全。
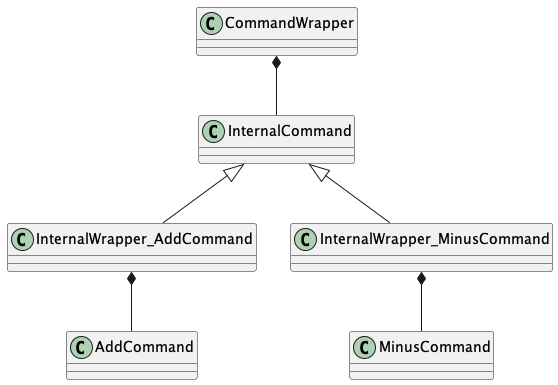
12.3.4. Wrapper
class CommandWrapper { struct InternalCommand { virtual void execute(const std::string& args) = 0; virtual ~InternalCommand() = default; }; template<typename T> struct InternalWrapper final : InternalCommand { T command; explicit InternalWrapper(T cmd) : command(std::move(cmd)) {} void execute(const std::string& args) override { command.execute(args); } }; std::unique_ptr<InternalCommand> impl; public: template<typename T> explicit CommandWrapper(T cmd) : impl(std::make_unique<InternalWrapper<T>>(std::move(cmd))) {} CommandWrapper() = default; void execute(const std::string& args) const { impl->execute(args); } }; std::unordered_map<std::string, CommandWrapper> commands; commands.emplace("add", CRTPWay::AddCommand()); commands.emplace("delete", CRTPWay::MinusCommand()); commands["add"].execute("by wrapper"); commands["delete"].execute("by wrapper");
Wrapper 更多是展示一种技巧,实际项目中应该较少用到,毕竟又用了虚函数又是CRTP。
本质是利用虚函数表统一了接口(定义一个内部 非模版基类 InternalCommand),真正的实例保存在内部包装器(继承InternalCommand,且是模版类),对实例的访问统一由内部基类代理。
要用统一的接口,则接口类必然不能是模版类,因为模板类实际对应的是不同的类型。
13. 代码示例
13.1. 模版
13.1.1. SFINAE
13.1.1.1. 检测类型是否具有特定成员
template<typename T> static std::true_type test_has_foo(decltype(T::foo()) *); template<typename T> static std::false_type test_has_foo(...); // 不定参数函数(C 风格的 ...),优先级最低,仅在上面的不匹配时才会用 template<typename T> constexpr bool has_foo = decltype(test_has_foo<T>(nullptr))::value; struct HasStringFooFunction { static std::string foo() { return "foo"; } }; struct HasIntFooFunction { static int foo() { return 42; } }; struct NoFooFunction {}; // 函数仅在 T::foo() 存在时才会被实例化 template <typename T> std::enable_if_t<has_foo<T>, decltype(T::foo())> call(T&&) { return T::foo(); } template <typename T> std::enable_if_t<!has_foo<T>, int> call(T&&) { return -1; } ASSERT_THAT(std::string("foo") == call(HasStringFooFunction()), "Should return 'foo' from HasStringFooFunction"); ASSERT_THAT(42 == call(HasIntFooFunction()), "Should return 42 from HasIntFooFunction"); ASSERT_THAT(-1 == call(NoFooFunction()), "Should return -1 from NoFooFunction");
13.1.1.2. 借助模板特化实现编译器条件分发
// 1. 定义一个 Trait 用于检测 T 是否有非 void 的 `value_type` template <typename T, typename = void> struct has_non_void_value_type : std::false_type {}; // 仅当 T 有 `value_type` 且 `value_type` 不是 void 时,特化为 std::true_type template <typename T> struct has_non_void_value_type<T, std::enable_if_t<!std::is_void_v<typename T::value_type>>> : std::true_type {}; // 2. 定义 TypePrinter 主模板,使用一个布尔参数控制特化 template <typename T, bool HasValueType = has_non_void_value_type<T>::value> struct TypeChecker; // 3. 特化:当 HasValueType 为 true 时,表示 T 有非 void 的 `value_type` template <typename T> struct TypeChecker<T, true> { static bool check(){ // std::cout << "T has a member type 'value_type'." << std::endl; return true; } }; // 特化:当 HasValueType 为 false 时,表示 T 没有 `value_type` 或 `value_type` 是 void template <typename T> struct TypeChecker<T, false> { static bool check(){ // std::cout << "hello world! T does not have a member type 'value_type'." << std::endl; return false; } }; // 测试结构体 struct WithValueType{ using value_type = int; }; struct WithoutValueType{}; struct WithVoidValueType{ using value_type = void; }; ASSERT_THAT(!TypeChecker<WithoutValueType>::check(), "WithoutValueType should not have value_type"); ASSERT_THAT(TypeChecker<WithValueType>::check(), "WithValueType should have value_type"); ASSERT_THAT(!TypeChecker<WithVoidValueType>::check(), "WithVoidValueType should not have non-void value_type");
这里有个有意思的地方, TypeChecker<T> 其实是先匹配到了主模版(只是声明,并无实现),然后经过编译期计算后再确定要使用的特化版本。
这和常规的模版匹配不太一样,常规的通常直接选中一个合适的模版并实例化,如果选中的模版只有声明,那链接阶段必然会失败。
这个行为上的变化,是不是和存在需要计算的模版参数有关?利用这个特点从而实现编译期条件分发的效果。
13.1.1.3. 较为优雅的方式
上面例子的思路是 通过主模版进行分发 , 下面这个例子是 主模版 fallback , 特化版本条件实例化 : (感觉更优雅)
template <typename T, typename Enable = void> // Enable 泛型符号都可以不用写 struct CallClass { static int call() { return -1; // 如果 T 没有 `foo` 成员函数,则返回 -1 } }; template <typename T> struct CallClass <T, std::enable_if_t<has_foo<T>>> { static auto call() -> decltype(T::foo()) { return T::foo(); // 如果 T 有 `foo` 成员函数,则调用它 } };
13.1.1.4. 使用 decltype 代替 enable_if
// [基于 decltype 的 SFINAE] 检测是否可以对T类型进行加法操作 template <typename, typename = void> struct is_addable : std::false_type {}; // void() 的作用是统一返回类型 // 如果直接写 decltype(std::declval<T>() + std::declval<T>()),每种类型的特化都会产生不同的模板参数 // 使用 void() 更明确表达了"只关心表达式是否有效,不关心返回类型", 主要是一种编程习惯,让意图更清晰 template <typename T> struct is_addable<T, decltype(void(std::declval<T>() + std::declval<T>()))> : std::true_type {}; ASSERT_THAT(is_addable<int>::value, "int should be addable"); ASSERT_THAT(is_addable<std::string>::value, "std::string should be addable"); ASSERT_THAT(!is_addable<void>::value, "void should not be addable");
std::declval<T>() 是一个编译时工具函数,用于在不构造对象的情况下获得类型T的引用。
- 只能在
decltype,sizeof等不求值上下文中使用 - 运行时调用会导致编译错误
- 返回T的右值引用(或左值引用,如果T已经是引用)
std::declval<int>() // 返回 int&& std::declval<string>() // 返回 string&& std::declval<int&>() // 返回 int&
// 问题:某些类型无法直接构造 class NoDefaultConstructor { public: NoDefaultConstructor(int x) {} // 没有默认构造函数 NoDefaultConstructor operator+(const NoDefaultConstructor& other); }; // 这样写会编译错误,因为无法构造对象 // decltype(NoDefaultConstructor() + NoDefaultConstructor()) // 解决方案:使用declval // 使用declval可以"假装"有这个对象 decltype(std::declval<NoDefaultConstructor>() + std::declval<NoDefaultConstructor>())