Python3
{Back to Index}
Table of Contents
- 1. 数据结构
- 2. 函数
- 3. 面向对象编程
- 4. 流程控制
- 5. 并发编程
- 6. 元编程
- 7. 参考文档
1 数据结构
1.1 序列类型
Python 标准库使用 C 实现了丰富的序列类型,如:
容器序列 (存放不同类型的数据 引用)
list, tuple, collections.deque
扁平序列 (存放一种类型的数据 值)
str, bytes, bytearray, memoryview, array.array
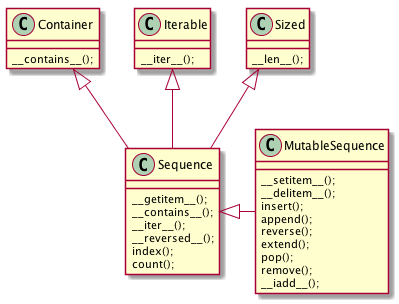
Figure 1: 可变序列 MutableSequence 和不可变序列 Sequence 的差异:(两个都是 collection.abc 中的类)
1.1.1 元组
元组通常被用作 不可变的列表 。 但元组的意义是 对数据的记录 :元组中的每个元素都存放了记录中一个字段的数据,外加这个字段的位置。 正是这个位置信息给数据赋予了意义。
1.1.2 具名元组
from collections import namedtuple
City = namedtuple('City', 'name country population coordinates')
tokyo = City('Tokyo', 'JP', 36.933, (35.689722, 139.691667))
log("tokyo", tokyo)
log("tokyo.population", tokyo.population)
log("tokyo.coordinates", tokyo.coordinates)
log("tokyo[1]", tokyo[1])
=========== tokyo ============ City(name='Tokyo', country='JP', population=36.933, coordinates=(35.689722, 139.691667)) ====== tokyo.population ====== 36.933 ===== tokyo.coordinates ====== (35.689722, 139.691667) ========== tokyo[1] ========== JP
除了从普通元组继承来的属性之外,具名元祖还有一些自己专用的属性:
log("City._fields", City._fields)
LatLong = namedtuple('LatLong', 'lat long')
delhi_data = ('Delhi NCR', 'IN', 21.935, LatLong(28.613889, 77.208889))
delhi = City._make(delhi_data)
log("delhi._asdict()", delhi._asdict())
print()
for key, value in delhi._asdict().items():
print(key + ':', value)
======== City._fields ========
('name', 'country', 'population', 'coordinates')
====== delhi._asdict() =======
OrderedDict([('name', 'Delhi NCR'), ('country', 'IN'), ('population', 21.935), ('coordinates', LatLong(lat=28.613889, long=77.208889))])
name: Delhi NCR
country: IN
population: 21.935
coordinates: LatLong(lat=28.613889, long=77.208889)
1.1.3 列表
切片操作里不包含区间范围的最后一个元素是 Python 的风格,这个习惯带来的好处如下:
- 当只有最后一个位置信息时,可以快速看出有几个元素:
range(3)和my_list[:3]都返回 3 个元素 - 当起止位置信息都可见时,可以快速计算出区间长度,即
stop - start - 可以利用任意一个下标把序列分割成不重叠的两部分,只需写成:
my_list[:3]和my_list[3:]
1.1.4 数组
如果需要一个只包含数字的列表,使用 array.array 比 list 更高效。
创建数组需要一个类型码,用来表示底层的 C 语言应存放怎样的数据类型。
from array import array
from random import random
floats = array('d', (random() for i in range(1000))) # 'd' 表示双精度浮点
log("floats[-1]", floats[-1])
========= floats[-1] ========= 0.970088201571867
1.1.5 内存视图
memoryview 是一个内置类,能让用户在 不复制内容的情况下 ,在数据结构之间 共享内存 。
# 通过改变数组中的一个字节来更新数组里某个元素的值
import array
numbers = array.array('h', [-2, -1, 0, 1, 2]) # 'h' 表示 16 位二进制整数
memv = memoryview(numbers)
# memoryview.cast 会把同一块内存里的内容打包成一个全新的 memoryview
memv_oct = memv.cast('B') # 'B' 表示无符号字符
memv_oct[5] = 4
log("numbers", numbers)
========== numbers ===========
array('h', [-2, -1, 1024, 1, 2])
1.1.6 双向队列
collection.deque 是一个 线程安全 ,可以快速从两端添加或删除元素的数据类型。
如果想要一种数据结构来存放 最近用到的几个元素 ,deque 是一个很好的选择。
from collections import deque
dq = deque(range(10), maxlen=10)
log("dq", dq)
dq.rotate(3)
log("dq.rotate(3)", dq)
dq.rotate(-4)
log("dq.rotate(-4)", dq)
dq.appendleft(-1)
log("dq.appendleft(-1)", dq)
dq.extend([11, 22, 33])
log("dq.extend([11, 22, 33])", dq)
============= dq ============= deque([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10) ======== dq.rotate(3) ======== deque([7, 8, 9, 0, 1, 2, 3, 4, 5, 6], maxlen=10) ======= dq.rotate(-4) ======== deque([1, 2, 3, 4, 5, 6, 7, 8, 9, 0], maxlen=10) ===== dq.appendleft(-1) ====== deque([-1, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10) == dq.extend([11, 22, 33]) === deque([3, 4, 5, 6, 7, 8, 9, 11, 22, 33], maxlen=10)
1.2 字典
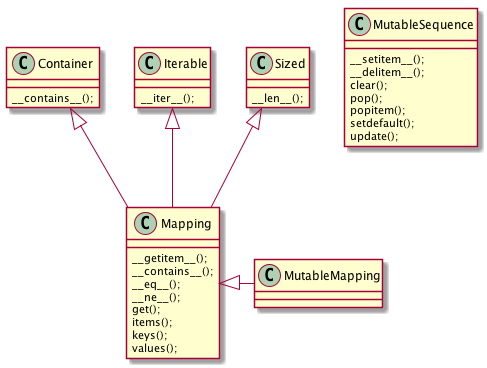
Figure 2: collections.abc 中的 MutableMapping 和它的超类
非抽象映射类型一般不会直接继承 collections.abc 中的抽象基类, 而是直接对 dict 或是 collections.UserDict 进行扩展。 这些抽象基类的主要作用是 形式化文档 ,可以和 isinstance 一起被用来判定某个数据是不是 广义上的映射类型 :
from collections import abc
d = {}
print(isinstance(d, abc.Mapping))
True
1.2.1 __missing__方法
映射类型在处理找不到的键的时候,都会涉及__missing__方法。 虽然基类 dict 没有定义这个方法,但是如果一个类继承了 dict ,然后提供了__missing__方法, 那么当__getitem__遇到找不到键的时候,Python 会自动调用它,而不是抛出 KeyError 异常。
__missing__ 方法只会被__getitem__调用(即使用表达式 d[k] )
1.2.2 散列表
散列表是一个 稀疏数组 (总是有空白元素的数组称为稀疏数组)。散列表中的单元叫做 bucket 。 每个 bucket 分为两部分,一个是键的引用,一个是值的引用。
Python 会设法保证大概还有三分之一的 bucket 是空的,所以在快要到达这个阈值的时候, 原有的散列表会被复制到一个更大的空间里面 。
1.2.2.1 加盐
str, bytes 和 datetime 对象的散列值计算过程中多了 随机加盐 这一步。
所加盐值是进程中一个常量,每次启动解释器都会生成一个不同的盐值。 随机盐值的加入是为了防止 DOS 攻击而采取的一种安全措施。
1.2.2.2 散列表算法
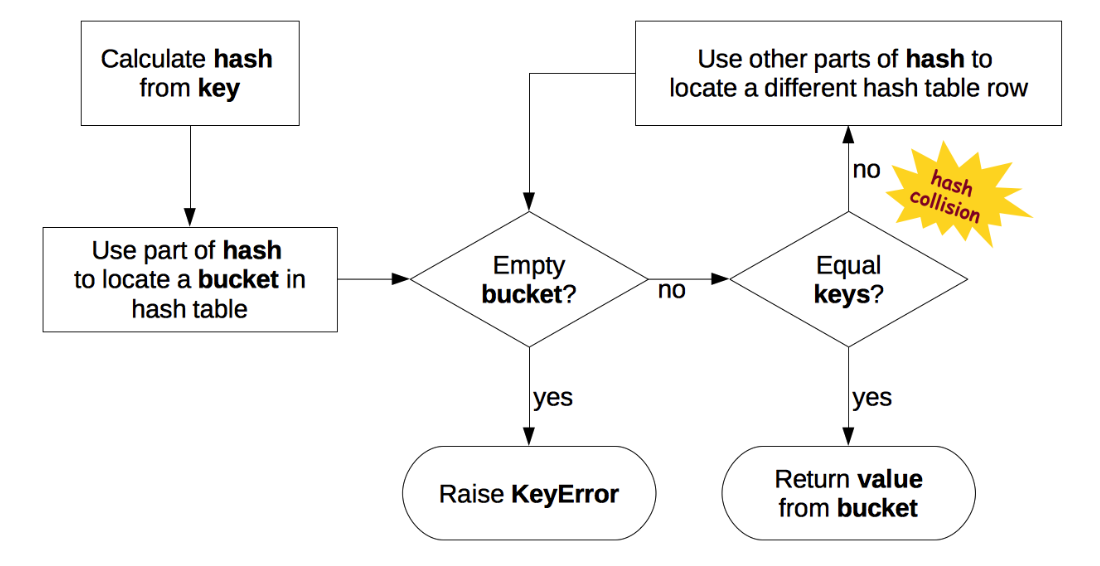
1.2.2.3 可散列对象必须满足的条件
- 支持
hash()函数,并且通过__hash__方法所得到的散列值是不变的 - 支持通过__eq__方法来检测相等性
- 若
a==b为真,则hash(a)==hash(b)也为真
如果一个含有自定义__eq__方法的类处于可变的状态,就不要在这个类中实现__hash__方法, 因为它的实例是不可散列的。
1.3 集合
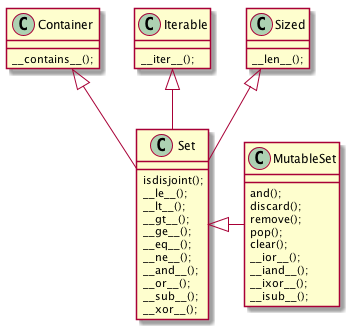
Figure 4: collections.abc 中的 MutableSet 和它的超类
1.3.1 合集,交集,差集
- 合集:
a | b - 交集:
a & b - 差集:
a - b
1.4 Unicode
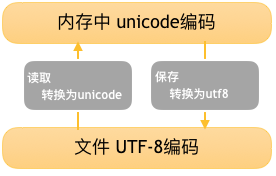
1.4.1 字符编码的工作方式
在计算机内存中,统一使用 Unicode 编码,当需要保存到硬盘或者需要传输的时候,就转换为 UTF-8 编码。
Python 的字符串在内存中以 Unicode 表示 ,一个字符对应若干个字节。 如果要在网络上传输,或者保存到磁盘上, 就需要把字符串变为以字节为单位的 bytes 。
2 函数
2.1 函数参数
函数参数定义的顺序必须是:必选参数、默认参数、可变参数、仅限关键字参数和关键字参数。
2.1.1 仅限关键字参数
仅限关键字参数可以用于限制关键字参数的名字。调用时必须传入参数名,否则将报错。
定义函数时若想指定 仅限关键字参数 ,要把它们放到前面有 * 的参数后面。
如果不想支持数量不定的定位参数,但是想支持仅限关键字参数,在函数签名中放一个 * 即可:
def f(a, *, b):
return a, b
print(f(1, b=3))
(1, 3)
如果函数定义中已经有了一个可变参数,后面跟着的仅限关键字参数就不再需要分隔符 * :
def f(a, *b, c):
return (a, b, c)
print(f(1, 2, 3, c=4))
(1, (2, 3), 4)
2.1.2 默认参数的陷阱
定义默认参数时,默认参数必须指向不可变对象。
def add_end(L=[]):
L.append('END')
return L
print(add_end())
print(add_end())
print(add_end())
['END'] ['END', 'END'] ['END', 'END', 'END']
出现这种现象的原因在于, 函数在定义的时候,默认参数 L 的值就被计算出来了,即 [] ,且该 引用 保存在函数属性__defaults__中。 每次调用该函数,如果改变了 L 的内容,__defaults__中的内容 也将随之改变 。
可以用 None 这个不可变对象来避免这种陷阱:
def add_end(L=None):
if L is None:
L = []
L.append('END')
return L
2.2 函数属性
class C: pass
obj = C()
def func(): pass
log("函数有而常规对象没有的属性", set(dir(func)) - set(dir(obj)))
================================ 函数有而常规对象没有的属性 =================================
{'__call__', '__code__', '__get__', '__name__', '__qualname__', '__defaults__', '__annotations__', '__kwdefaults__', '__globals__', '__closure__'}
| 名称 | 类型 | 说明 |
|---|---|---|
| __annotations__ | dict | 参数和返回值注解 |
| __call__ | method-wrapper | 可调用对象协议 |
| __closure__ | tuple | 闭包,即自由变量的绑定 |
| __code__ | code | 编译成字节码的函数元数据和定义体 |
| __defaults__ | tuple | 参数默认值 |
| __get__ | method-wrapper | 只读描述符协议 |
| __globals__ | dict | 函数所在模块中的全局变量 |
| __kwdefaults__ | dict | 仅限关键字形式参数默认值 |
| __name__ | str | 函数名 |
| __qualname__ | str | 函数限定名 |
2.3 局部变量作用域规则
b = 6
def f(a):
print(a)
print(b)
b = 9
try:
f(3)
except Exception as e:
print("Exception:", e)
3 Exception: local variable 'b' referenced before assignment
编译函数定义体时,由于在函数中对 b 进行了赋值,因此 Python 判定 b 为局部变量。 当函数被调用时,Python 尝试获取局部变量 b 时,发现 b 没有绑定值,于是报错。
这是 Python 的 设计选择 :不要求声明变量,但是假定 在函数定义体中赋值的变量是局部变量 。
2.4 闭包
闭包指的是延伸了作用域的 函数 ,其中包含函数定义体中引用了, 但是不在定义体中定义的 非全局变量 (自由变量)。
def make_averager():
series = []
def averager(new_value):
series.append(new_value)
total = sum(series)
return total/len(series)
return averager
avg = make_averager()
print(avg(10))
print(avg(11))
print(avg(12))
10.0 10.5 11.0
2.4.1 自由变量定义
自由变量指的是未在 local 作用域中绑定的变量。

2.4.2 闭包元信息(__code__, __closure__)
局部变量和自由变量的名称保存在__code__属性中:
log("avg.__code__.co_varnames", avg.__code__.co_varnames)
log("avg.__code__.co_freevars", avg.__code__.co_freevars)
=========================== avg.__code__.co_varnames ===========================
('new_value', 'total')
=========================== avg.__code__.co_freevars ===========================
('series',)
自由变量的绑定值保存在__closure__属性中:
log("avg.__closure__", avg.__closure__)
=============================== avg.__closure__ ================================ (<cell at 0x111aff978: list object at 0x111954dc8>,)
__closure__ 中的各个元素对应于 __code__.co_freevars 中的一个名称。
这些元素是 cell 对象,该对象的 cell_contents 属性保存着真正的值:
log("avg.__closure__[0].cell_contents", avg.__closure__[0].cell_contents)
======================= avg.__closure__[0].cell_contents ======================= [10, 11, 12]
2.4.3 nonlocal
def make_averager():
count = 0
total = 0
def averager(new_value):
count += 1
total += new_value
return total / count
return averager
avg = make_averager()
try:
print(avg(10))
except Exception as e:
print(e)
local variable 'count' referenced before assignment
造成上述错误的原因在于,如果 尝试重新绑定 ,例如 count = count + 1 ,
其实会 隐式创建局部变量 count ,从而导致错误。
同时,这样一来, count 就不可能是自由变量了,不会保存在闭包中。
Python 3 引入了 nonlocal 声明,它的作用是 把变量标记为自由变量 :
def make_averager():
count = 0
total = 0
def averager(new_value):
nonlocal count, total
count += 1
total += new_value
return total / count
return averager
avg = make_averager()
try:
print(avg(10))
except Exception as e:
print(e)
10.0
2.4.4 闭包的陷阱
闭包中不要引用任何可能会变化的变量 :
def count():
fs = []
for i in range(1, 4):
def f():
return i*i
fs.append(f)
return fs
f1, f2, f3 = count()
print(f1(), f2(), f3())
9 9 9
如果一定要引用会变化的变量,可以再创建一个函数:
def count():
def f(j):
def g():
return j*j
return g
fs = []
for i in range(1, 4):
fs.append(f(i))
return fs
f1, f2, f3 = count()
print(f1(), f2(), f3())
1 4 9
2.5 参数化装饰器
参数化装饰器本质上是一个 装饰器工厂函数 :把参数化传给它,返回一个装饰器, 然后再把这个装饰器应用到要装饰的函数上:
def decorator(*args, **kwargs):
def decorate(func):
pass
return decorate
3 面向对象编程
3.1 对象的比较(== 与 is)
== 比较两个对象的值 (对象中保存的数据),而 is 比较对象的标识。
a==b 等同于 a.__eq__(b) 。
继承自 object 的__eq__方法比较两个对象的 ID ,结果与 is 一样。
但多数内置类型使用更有意义的方式覆盖了__eq__方法,会考虑对象属性的值。
3.2 对象的深复制与浅复制
构造方法或 [:] 做的是浅复制,即复制了 最外层 容器,
副本中的元素是源容器中元素的引用。
copy 模块提供的 deepcopy 和 copy 函数能为任意对象做深复制和浅复制:
import copy
class A:
def __init__(self):
self.container = []
a = A()
a.container.append(1)
a_copy = copy.copy(a)
a_deepcopy = copy.deepcopy(a)
a.container.append(2)
log("a_copy.container", a_copy.container)
log("a_deepcopy.container", a_deepcopy.container)
=============================== a_copy.container =============================== [1, 2] ============================= a_deepcopy.container ============================= [1]
3.3 垃圾回收
如果两个对象相互引用,当它们的引用 只存在两者之间时 ,垃圾回收程序会判断它们都无法获取, 进而把它们 都销毁 。
3.3.1 监控对象回收(weakref.finalize)
import weakref
s = {1, 2, 3}
ender = weakref.finalize(s, lambda: print("Gone with the wind ..."))
print(ender.alive)
del s
True Gone with the wind ...
3.4 弱引用
弱引用经常用在缓存中,即需要引用对象,但又不让对象存在的时间超过所需时间。
3.4.1 创建弱引用
弱引用是可调用对象,如果对象存在,调用弱引用可以获取对象,否则返回 None :
import weakref
a = {0, 1}
wref = weakref.ref(a)
print(wref())
{0, 1}
3.4.2 weakref.WeakValueDictionary
WeakValueDictionary 类实现的是一种可变映射, 里面的值是对象的弱引用 。 被引用的对象在程序中的其他地方被当作垃圾回收后,对应的键会自动从 WeakValueDictionary 中删除。 因此,WeakValueDictionary 经常用于缓存。
import weakref
class Cheese:
def __init__(self, kind):
self.kind = kind
stock = weakref.WeakValueDictionary()
catalog = [Cheese('Read Leicester'), Cheese('Tilsit'), Cheese('Brie'), Cheese('Parmesan')]
for cheese in catalog:
stock[cheese.kind] = cheese
print(sorted(stock.keys()))
del catalog
del cheese
print(sorted(stock.keys()))
['Brie', 'Parmesan', 'Read Leicester', 'Tilsit'] []
3.4.3 weakref.WeakKeyDictionary
与 WeakValueDictionary 对应的是 WeakKeyDictionary ,后者的键是弱引用。
3.4.4 weakref.WeakSet
保存元素弱引用的集合类。元素没有强引用时,集合会把它删除。
如果 一个类需要知道所有实例 ,一种好的方案是创建一个 WeakSet 类型的类属性,用以保存实例的引用。
3.4.5 弱引用的局限
不是每个 Python 对象都可以作为弱引用的目标 (或称所指对象) 。
list 和 dict 实例不能作为所指对象, 但是它们的子类可以 。
int 和 tuple 实例不能作为弱引用的目标,甚至它们的 子类也不行 。
这些局限是内部优化导致的结果。
3.4.6 对象支持弱引用(__weakref__属性)
为了让对象支持弱引用,必须要有 __weakref__ 这个属性,用户定义的类中默认就有这个属性。
如果类中定义了 __slots__ 属性,而且想把实例作为弱引用的目标,
那么必须把 __weakref__ 添加到 __slots__ 中。
3.5 抽象类
3.5.1 内置抽象基类
大多数内置抽象基类在 collection.abc, numbers 和 io 模块中定义。
collection.abc 中的抽象基类最常用,其次是 numbers 。
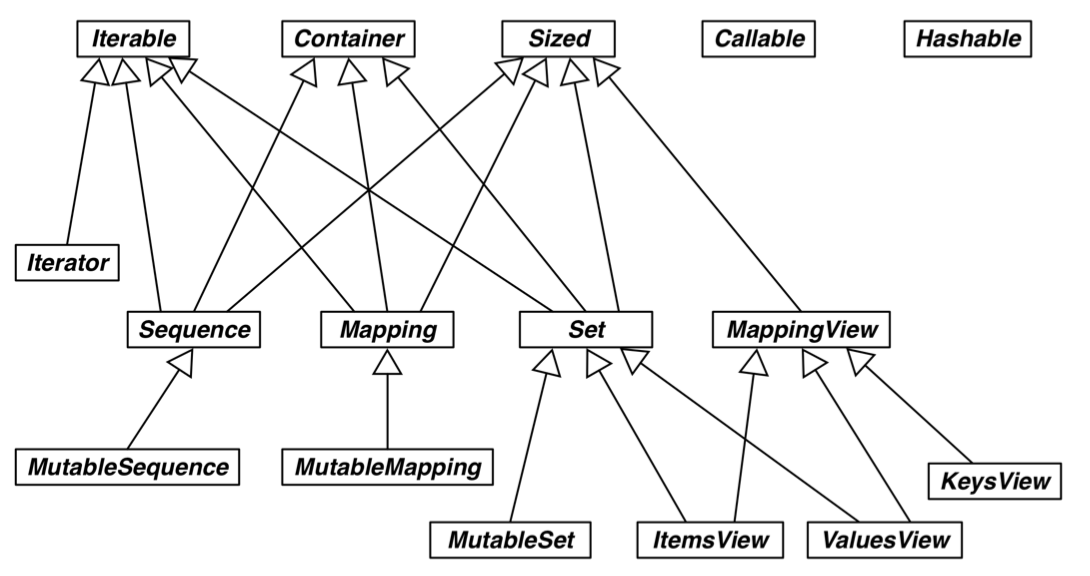
Figure 7: collections.abc 模块中各个抽象基类的 UML 类图
3.5.2 自定义抽象基类
抽象基类中的抽象方法可以有实现代码。
即使实现了, 子类也必须覆盖抽象方法 ,但是在子类中可以使用 super() 函数调用抽象方法。
与其他装饰器一起使用时, @abstractmethod 应放在 最里层 ,
即 @abstractmethod 与 def 之间不能有其他装饰器。
from abc import ABC, abstractmethod
class Pet(ABC):
@classmethod
def from_name(cls, name):
for s_cls in cls.__subclasses__(): # 注意 __subclasses__ 的用法
if name == s_cls.__name__.lower():
return s_cls()
@abstractmethod
def hello(self):
pass
class Dog(Pet):
def hello(self):
print("WonWonWon")
Pet.from_name("dog").hello()
WonWonWon
3.5.3 虚拟子类
虚拟子类的作用在于:即使不通过继承,也可以把一个类注册为抽象基类的子类。
当注册了抽象子类,必须保证所注册的类忠实地实现了抽象基类定义的接口(虽然 Python 并不在注册时做检查), 否则在运行时可能会抛异常。
注册虚拟子类的方式是在抽象基类上调用 register 方法,
register 方法通常作为普通函数调用,也可以作为装饰器使用。
这么做之后,注册的类会变成抽象基类的虚拟子类,而且 issubclass 和 isinstance 都能识别,
但是注册的类不会从抽象基类中继承任何方法或属性 。
@Pet.register
class Cat:
pass
class Bird(list):
pass
Pet.register(Bird)
log("issubclass(Cat, Pet)", issubclass(Cat, Pet))
log("isinstance(Bird(), Pet)", isinstance(Bird(), Pet))
log("Bird.__mro__", Bird.__mro__)
==== issubclass(Cat, Pet) ==== True == isinstance(Bird(), Pet) === True ======== Bird.__mro__ ======== (<class '__main__.Bird'>, <class 'list'>, <class 'object'>)
虚拟子类的 __mro__ 属性中没有虚拟基类,说明了虚拟子类并没有从虚拟基类中继承任何方法。
3.5.3.1 __subclasses__
该方法返回类的直接子类列表, 不含虚拟子类 。
3.5.3.2 _abc_registry
只有抽象基类才有这个 属性 ,其值是 WeakSet 对象,即抽象基类注册的虚拟子类的弱引用。
3.6 继承
直接子类化内置类型 (如 dict, list 或 str) 容易出错,
因为内置类型的方法通常会忽略用户覆盖的方法。1
不要子类化内置类型 ,用户自己定义的类应该继承 collection 模块中的类,
如 UserDict, UserList 和 UserString ,这些类 做了特殊设计 ,易于扩展。
3.7 classmethod / staticmethod 装饰器
classmethod= 最常见的用途是 定义备选构造方法 。
staticmethod 就是 普通的函数 ,只是碰巧在类的定义体中。
该装饰器 并不是很重要 ,因为可以在同一模块中该类的前后定义函数即可达到同样的效果。
3.8 __slots__属性
默认情况下,Python 在各个实例中名为 __dict__ 的字典里存储实例属性。
为了使用底层的散列表提升访问速度,字典会消耗大量内存。
如果要处理数百万个属性不多的实例,通过 __slots__ 类属性,能节省大量内存。
其本质是让解释器在元组中存储实例属性,而不是使用字典。
继承自超类的 __slots__ 属性 没有效果 ,Python 只会使用 各个类中自己定义 的 __slots__ 属性。
不要使用 __slots__ 禁止类的用户新增实例属性,使用 __slots__ 是 为了优化,不是为了约束。
3.8.1 节省的内存也可能被再次吃掉
如果把 __dict__ 这个名称添加到 __slots__ 中,
实例会在元祖中保存各个实例的属性,同时还支持动态创建属性,但这样就失去了节省内存的功效。
3.9 __getattr__方法
对于 my_obj.x 表达式,Python 会检查该实例有没有名为 x 的属性,如果没有,到类 my_obj.__class__ 中查找;
如果仍然没找到,则顺着继承树继续查找。
如果依旧找不到,则调用 my_obj 所属类中定义的 __getattr__ 方法,传入 self 和属性名称的字符串形式 'x' 。
多数时候,如果实现了 __getattr__ 方法,那么也要定义 __setattr__ 方法,以防对象的行为不一致。
4 流程控制
4.1 内置的 iter 函数
当需要迭代对象 x 时,会自动调用 iter(x) 。内置的 iter 函数有以下作用:
- 检查对象是否实现了
__iter__方法,如果实现了就调用它,获取一个迭代器。 - 如果没有实现
__iter__方法,但是实现了__getitem__方法,Python 会创建一个迭代器,尝试按顺序(从索引0开始)获取元素。 - 如果尝试失败,则抛出
TypeError异常。
4.2 生成器
生成器保存的是算法 ,每次调用 next(g) ,就计算出 g 的下一个元素的值。
直到计算到最后一个元素,没有更多的元素时,抛出 StopIteration 异常。
当 Python 函数定义体中有 yield 关键字,该函数就是生成器函数。
调用生成器函数时,会返回一个生成器对象。也就是说生成器函数是生成器工厂。
生成器表达式本质上是生成器函数的语法糖。
4.3 for/else, while/else, try/else
在所有情况下,如果因为异常或者 return,break 或 continue 语句导致控制权跳到了块之外,else 子句也会被跳过。
for/else
仅当 for 循环运行完毕时 (即 for 循环没有被 break 语句中止) 才运行 else 块。
while/else
仅当 while 循环因为条件为假值而退出时 (即 while 循环没有被 break 语句中止) 才运行 else 块。
try/else
仅当 try 块中没有异常抛出时才运行 else 块, else 子句抛出的异常不会由前面的 except 子句处理。
4.4 上下文管理协议(with)
with 语句的目的是简化 try/finally 模式 。
上下文管理器协议包含__enter__和__exit__两个方法:
- with 语句开始运行时,会在上下文管理器对象上调用__enter__方法。
- with 语句运行结束后,会在上下文管理器对象上调用__exit__方法,以此扮演 finally 子句的角色。
__exit__方法如果返回 True 之外的值 (包括 None) ,则 with 块中的任何异常都会向上冒泡。 (返回 True ,即告诉解释器,异常已经处理了)
不要自己造轮子2
4.5 协程
协程是指一个过程,这个过程与调用方协作,产出由调用方提供的值。
协程中的关键字 yield 可以视作控制流程的方式。
4.5.1 协程的状态
可以使用 inspect.getgeneratorstate() 获取协程四个状态中的一个:
- GEN_CREATED:等待开始执行
- GEN_RUNNING:正在执行(只有在多线程应用中才能看到这个状态)
- GEN_SUSPENDED:在 yield 表达式处暂停
- GEN_CLOSED:执行结束
4.5.2 执行过程举例

- 调用
next(my_coro2),打印第一个消息,然后执行 yield a ,产出数字 14 - 调用
my_coro2.send(28),把 28 赋值给 b ,打印第二个消息,然后执行yield a + b,产出 42 - 调用
my_coro2.send(99),把 99 赋值给 c ,打印第三个消息,协程终止
注意,各个阶段都在 yield 表达式中结束,而且下一个阶段都从那一行代码开始,然后再把 yield 表达式的值赋给变量。
4.5.3 预激(prime)
如果不预激,则协程没什么用,即调用 send() 之前,一定要先调用 next() 。
使用 yield from 调用协程时,会 自动预激 。
标准库里的 asyncio.coroutine 装饰器不会预激协程,兼容 yield from 语法。
4.5.4 协程的终止和异常处理
协程中未处理的异常会向上冒泡,传给调用协程的对象,未处理的异常会导致协程终止。
4.5.4.1 generator.throw()
generator.throw(exc_type[, exc_value[, traceback]])
该方法会导致生成器在暂停的 yield 表达式处抛出指定的异常。
如果生成器内部处理了该异常,代码会向前执行到下一个 yield 表达式处, 而产出的值会成为该方法的返回值 。
如果生成器内部没有处理这个异常,异常会向上冒泡,传到调用方的上下文中。
4.5.4.2 generator.close()
该方法使得生成器在暂停的 yield 表达式处抛出 GeneratorExit 异常。
如果生成器内部没有处理这个异常,调用方不会报错。
捕获到 GeneratorExit 异常后,生成器 不能再产出值 ,否则解释器会抛出 RuntimeError 异常。
如果不管协程如何结束都需要做清理工作,需要把协程定义体中相关的代码放入 try/finally 块中。
GC 时会调用 close() (try-finally in Python 3 generator) 。
4.5.5 yield from
yield from 主要功能是创建 双向通道 ,将内层生成器直接与外层生成器的 调用方 联系起来。
这样两者可以直接发送和产出值,还可以直接传入异常对象。
即当一个生成器函数需要产出另一个生成器生成的值,可以使用这个语法:
def chain(*iterables):
for i in iterables:
yield from i
print(list(chain('ABC', range(3))))
['A', 'B', 'C', 0, 1, 2]
yield from 结构通常会和 asyncio 模块结合起来实现异步编程。
4.5.5.1 yield from 工作原理
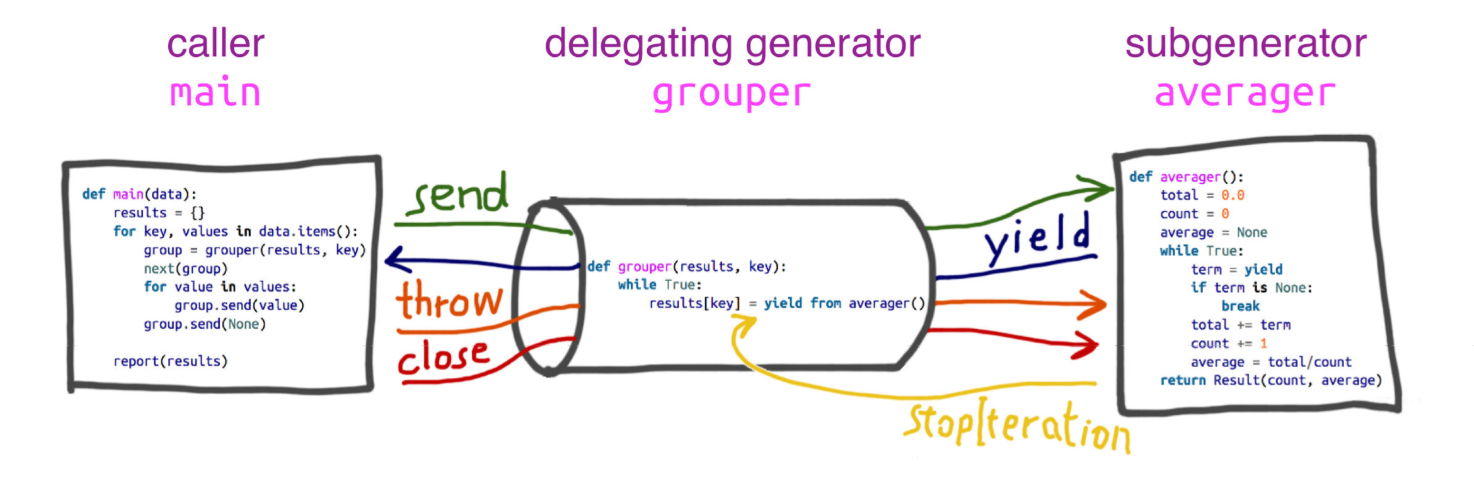
委派生成器相当于 管道 ,可以把任意数量的委派生成器连接在一起,
这个管道最终要以一个只使用 yield 表达式的简单生成器结束 (也能以任何可迭代对象结束) 。
任何 yield from 链都必须 由客户驱动 ,即在最外层委派生成器上调用 next(), send() 方法。
(也可以隐式调用,如使用 for 循环)
yield from x 表达式对 x 对象所做的第一件事就是调用 iter(x) ,从中获取迭代器。
因此,只要实现了 __next__ 方法, yield from 就能处理得了。
不过,引入 yield from 结构的主要目的是为了支持实现了__next__, send, close 和 throw 方法的生成器。
4.5.5.2 yield from 对异常和终止的处理
- 传入委派生成器的异常,除了 GeneratorExit 之外都传给子生成器的
throw()方法。 如果调用throw()方法抛出 StopIteration 异常,委派生成器恢复运行。 StopIteration 之外的异常会向上冒泡,传给委派生成器。(即 委派生成器若提前结束迭代,则子生成器也会自动结束迭代 ) - 如果把 GeneratorExit 异常传入委派生成器,或者在委派生成器上调用
close()方法, 则会在子生成器上调用close()方法 (如果它有的话) 。 如果子生成器调用close()方法导致异常抛出,则异常会向上冒泡,传给委派生成器, 如果没有异常抛出,则委派生成器会抛出 GeneratorExit 异常。(即 关闭委派生成器也将自动关闭子生成器 )
4.5.5.3 yield from 表达式的值
yield from subgen 结构会在内部自动捕获 StopIteration 异常。
subgen 通过 return 关键字返回的值会赋给 StopIteration 异常的 value 属性,该值最终成为 yield from 表达式的值。
5 并发编程
5.1 全局解释锁 (GIL)
CPython 解释器本身不是线程安全的,因此有全局解释器锁 (GIL) , 一次只允许使用一个线程执行 Python 字节码。因此,一个 Python 进程不能同时使用多个 CPU 。
5.1.1 I/O 密集型操作
标准库中所有执行阻塞型 I/O 操作的函数,在等待操作系统返回结果时都会释放 GIL 。
这意味着在 Python 语言这个层次上可以使用多线程,I/O 密集型的程序能从中受益。
( time.sleep() 函数也会释放 GIL)
5.1.2 CPU 密集型操作
使用 ProcessPoolExecutor 类把工作分配给多个进程处理可以实现真正的并行运算。
因此,如果需要做 CPU 密集型处理,可以使用它绕开 GIL ,从而利用所有可用的 CPU 。 (多个 Python 进程有各自独立的 GIL 锁,互不影响)
5.2 基于 concurrent.futures 模块的并发编程
concurrent.futures 模块的主要特色是 ThreadPoolExecutor 和 ProcessPoolExecutor 类, 这两个类实现的接口能分别在不同的线程或进程中执行可调用的对象。
通常情况下 future 对象不应由用户创建,而是由并发框架 (concurrent.futures 或 asyncio) 来实例化。
5.2.1 Executor.map(func, *iterables, timeout=None, chunksize=1)
chunksize 只对 ProcessPoolExecutor 有用,用于切分 iterables ,提高运行效率。 因为 future 结果的返回涉及到 IPC ,如果每个进程每次消耗 iterables 中的一个数据,整个过程涉及多个 IPC ,这样效率不高; 但如果对 iterables 进行切分,N 个 数据同时交给一个进程进行处理,运算结果通过一个 IPC 一并返回,这样就可以提升效率。
返回值是一个迭代器,迭代器的__next__方法调用各个 future 对象的 result 方法,得到各个 future 的结果。
from concurrent.futures import ThreadPoolExecutor
import time
def sleep_and_double(value):
time.sleep(value)
return value * 2
with ThreadPoolExecutor(max_workers=4) as executor:
time0 =time.time()
values = executor.map(sleep_and_double, [3, 2, 1])
time_delta = time.time() - time0
print("time consumed0: ", time_delta)
print(values)
time0 =time.time()
print([v for v in values])
time_delta = time.time() - time0
print("time consumed1: ", time_delta)
time consumed0: 0.009264230728149414 <generator object Executor.map.<locals>.result_iterator at 0x110912e60> [6, 4, 2] time consumed1: 2.9983181953430176
5.2.2 Executor.sumit(fn, *args, **kwargs)
with ThreadPoolExecutor(max_workers=1) as executor:
time0 = time.time()
future = executor.submit(sleep_and_double, 3)
time_delta = time.time() - time0
print("time consumed0: ", time_delta)
time0 = time.time()
print(future.result())
time_delta = time.time() - time0
print("time consumed1: ", time_delta)
time consumed0: 0.00031113624572753906 6 time consumed1: 3.004795789718628
5.2.3 concurrent.futures.as_completed(fs, timeout=None)
如果调用 finished = as_completed(fs, timeout) 后,经过 timeout 时间后仍然无法获取 next(finishes).result() 的值,
则抛出 concurrent.futures.TimeoutError 异常。
from concurrent import futures
fs = []
with ThreadPoolExecutor(max_workers=5) as executor:
for i in [5, 4, 3, 2, 1]:
f = executor.submit(sleep_and_double, i)
fs.append(f)
time0 = time.time()
finishes = futures.as_completed(fs)
time_delta = time.time() - time0
print("time consumed0: ", time_delta)
time0 = time.time()
print([f.result() for f in finishes])
time_delta = time.time() - time0
print("time consumed1: ", time_delta)
time consumed0: 2.86102294921875e-06 [2, 4, 6, 8, 10] time consumed1: 4.999896287918091
fs 可以是一个字典,把各个 future 对象映射到其他有用的数据上, 这样尽管 future 生成的结果顺序可能乱了,依然便于使用结果做后续的处理:
from concurrent import futures
from concurrent.futures import ThreadPoolExecutor
import time
fs = {}
def sleep_and_double(value):
time.sleep(value)
return value * 2
with ThreadPoolExecutor(max_workers=5) as executor:
for i in [5, 4, 3, 2, 1]:
f = executor.submit(sleep_and_double, i)
fs[f] = i
time0 = time.time()
finishes = futures.as_completed(fs)
time_delta = time.time() - time0
print("time consumed0: ", time_delta)
time0 = time.time()
for f in finishes:
print("#{} => {}".format(fs[f], f.result()))
time_delta = time.time() - time0
print("time consumed1: ", time_delta)
time consumed0: 7.867813110351562e-06 #1 => 2 #2 => 4 #3 => 6 #4 => 8 #5 => 10 time consumed1: 5.001190900802612
5.3 基于 asyncio 包的并发编程
- asyncio 包使用的协程是有严格定义的,因此 适合 asyncio API 的协程在定义体中必须使用 yield from ,而不能用 yield 。
- 适合 asyncio 的协程必须由调用方驱动,由调用方通过
yield from coro_or_future驱动;或者把协程传给 asyncio 包中的某个函数(如asyncio.async()),从而 驱动协程 。 - @asyncio.coroutine 装饰器应该始终应用在协程上。
5.3.1 基本思想 (面向事件编程)
- 在一个单线程中使用主循环依次激活队列里的协程
- 各个协程向前执行几步,然后把控制权让给主循环
- 主循环再激活队列里的下一个协程
编写基于 asyncio 的程序需注意下述细节:
- 编写的协程链始终通过把最外层委派生成器传给 asyncio 包中的某个函数驱动,例如
loop.run_until_complete()。即我们的代码不通过调用next()函数或send()方法驱动协程。驱动由 asyncio 包实现的事件循环去做。 - 编写的协程链最终通过
yield from把职责委托给 asyncio 包中的某个协程函数,如yeild from asyncio.sleep(),或者其他库中实现高层协议的协程,如response = yield from aiohttp.request('GET', url)。也就是说, 最内层的子生成器是库中真正执行 I/O 操作的函数,而不是我们自己编写的函数。
概括起来就是:使用 asyncio 包时,我们编写的代码中包含委派生成器, 而生成器最终把职责 委托 给 asyncio 包或第三方库中的协程。 这种处理方式相当于 架起了管道 ,让 asyncio 事件循环驱动执行低层异步 I/O 操作的库函数。
5.3.2 @asyncio.coroutine 装饰器(或 async 关键字)
交给 asyncio 处理的协程要使用 @asyncio.coroutine 装饰,这虽不是强制要求,但是建议这么做。
因为这样能在一众普通函数中把协程凸显出来,也有助于调试: 如果还没从协程中产出值,协程就被垃圾回收了,可以发出警告。
也可以使用 async 关键字。
5.3.3 asyncio.Future
asyncio.Future 类的目的是与 yield from 一起使用,通常 不需要 使用以下方法:
asyncio.Future.add_done_callback()
因为可以直接把在 Future 运行结束后执行的操作放在 yield from 表达式后面。
asyncio.Future.result()
因为 yield from 从 Future 对象中产出的值就是结果。
5.3.4 asyncio.Task
asyncio.Task 是 asyncio.Future 的子类,与 threading.Thread 地位对等,可以理解为协程中的可调度单元。
5.3.4.1 创建 Task 对象
asyncio.async(coro_or_future, *, loop=None)
如果第一个参数是 Future 或 Task 对象,则原封不动地返回; 如果是协程,则会调用
loop.create_task()方法创建 Task 对象。loop 关键词参数是可选的,用于传入事件循环,如果没有传入,则将调用
asyncio.get_event_loop()获取。BaseEventLoop.create_task(coro)
5.3.5 APIs
5.3.5.1 BaseEventLoop.run_in_executor(executor, func, *args)
asyncio 的事件循环在背后维护着一个 ThreadPoolExecutor 对象, 可以调用 run_in_executor 方法,把可调用对象发给它执行。
第一个参数是 Executor 实例,如果为 None ,则使用默认的 ThreadPoolExecutor 实例。
5.3.5.2 asyncio.as_complete(fs, *, loop=None, timeout=None)
import asyncio
import time
async def foo(seconds):
await asyncio.sleep(seconds)
return seconds
async def coro():
fs = [foo(10), foo(5), foo(1)]
for f in asyncio.as_completed(fs):
time0 = time.time()
result = await f
print(result, "delta", time.time() - time0)
asyncio.get_event_loop().run_until_complete(coro())
5.3.5.3 asyncio.Semaphore(value=1, *, loop=None)
Semaphore 类用于限制并发请求数量。
Semaphore 对象维护一个内部计数器:
- 如果在对象上调用
acquire()方法,计数器递减; - 如果调用
release()方法,计数器递增。
可以把 Semaphore 对象 当作上下文管理器使用 。
time0 = time.time()
async def foo(semaphore):
with (await semaphore):
await asyncio.sleep(2)
print("time delta:", time.time() - time0)
async def coro():
semaphore = asyncio.Semaphore(3)
fs = [foo(semaphore) for _ in range(5)]
for f in asyncio.as_completed(fs):
await f
asyncio.get_event_loop().run_until_complete(coro())
5.3.5.4 asyncio.wait(futures, *, loop=None, timeout=None, return_when=ALL_COMPLETED)
参数是一个由 Future 或协程构成的可迭代对象,wait 会分别把各个协程包装进一个 Task 对象。 wait 是协程函数,因此它 不会阻塞 ,默认行为是等传给它的所有协程运行完毕后结束。
import random
async def foo():
sec = random.randint(1, 3)
await asyncio.sleep(sec)
return sec
to_do = [foo() for _ in range(10)]
wait_coro = asyncio.wait(to_do)
result = asyncio.get_event_loop().run_until_complete(wait_coro)
log("result", result)
6 元编程
6.1 属性查找顺序
6.1.1 从类中查找属性
使用 C.name 引用类对象 C 的一个属性时,查询操作如下:
- 当 name 是
C.__dict__中的一个键时, C.name 将从C.__dict__['name']中提取值 v。如果 v 是一个描述器,则 C.name 的值就是type(v).__get__(v, None, C),否则,C.name 的值为 v - 否则,C.name 将委托查找 C 的基类
- 否则引发 AttributeError
6.1.2 从实例中查找属性
obj.attr 这样的表达式 不会从 obj 开始寻找 attr ,而是从 obj.__class__ 开始,
仅当类中没有名为 attr 的描述符时,才会在 obj 实例中寻找。
使用 x.name 引用类 C 的实例 x 的一个属性时,查询操作如下:
- 当 name 作为一个覆盖描述器 v 的名称在类 C (或 C 的某个祖先类)中被找到,x.name 的值就是
type(v).__get__(v, x, C) - 否则,当 name 是
x.__dict__中的一个键时,返回x.__dict__['name'] - 否则,x.name 将委托查找 x 的类,即查找 C.name
- 如果 C 定义或继承了特殊方法
__getattr__,则调用C.__getattr__(x, 'name'),而不是引发 AttributeError,然后根据__getattr__返回一个合适的值或者引发 AttributeError
6.2 特殊方法__new__
- 通常把__init__方法称为构造方法,其实,用于构建实例的是特殊方法__new__
- __new__是类方法,由于 使用了特殊方式处理 ,因此不必使用 @classmethod 装饰器
- 该方法必须返回一个实例,返回的实例会作为 第一个参数 (self) 传给__init__方法
- __init__方法其实称为初始化方法更为合适(真正的构造方法是__new__)
- 几乎不需要自定义__new__方法,从 object 类继承的实现已经足够了
__new__方法也可以返回其他类的实例,此时,解释器不会调用__init__方法
Python 构建对象的过程可以用下述伪代码概括:
def object_maker(the_class, some_arg):
new_object = the_class.__new__(some_arg)
if isinstance(new_object, the_class):
the_class.__init__(new_object, some_arg)
return new_object
# 下述两个语句作用等效
# x = Foo('bar')
# x = object_maker(Foo, 'bar')
6.3 property(fget=None, fset=None, fdel=None, doc=None)
- property 经常用作装饰器,但它其实是一个类
- 如果没有把函数传给某个可选参数,返回的 property 对象就不允许执行相应的操作
- property 对象都是类属性,但是管理的其实是实例属性的存取
6.4 动态属性编程 API
6.4.1 特殊属性
6.4.1.1 __class__属性
6.4.1.2 __dict__属性
6.4.1.3 __slots__属性
处理完类的定义体后再修改__slots__没有任何作用。
6.4.2 内置函数
6.4.2.1 dir([obj])
- 不会列出__dict__属性本身,但会列出其中的键
- 不会列出类的几个特殊属性(如__mro__, __bases__和__name__)
- 如果没有可选参数,则列出当前作用域中的名称
6.4.2.2 getattr(obj, name[, default])
6.4.2.3 hasattr(obj, name)
该函数的实现方法其实是调用 getattr(obj, name) ,并检查是否抛出 AttributeError 异常。
6.4.2.4 setattr(obj, name, value)
6.4.2.5 vars([obj])
- 返回对象的__dict__属性
- 如果实例所属的类定义了__slots__属性,则 vars 函数不能处理这个实例( dir 函数能处理)
- 如果没有参数,vars 函数的作用和 locals 函数一样,返回本地作用域的字典
6.4.3 特殊方法
- 使用点号或内置的 getattr, hasattr 和 setattr 函数存取对象属性会触发下述列表中对应的特殊方法
- 直接通过实例的__dict__读写属性不会触发这些特殊方法,通常 使用这种方式跳过特殊方法
- 相比定义这些特殊方法,使用 property 或 descriptor 相对不容易出错
为确保调用特殊方法成功,特殊方法必须定义在类体上,而不能在对象的实例字典中定义。 此外,特殊方法不会被同名实例属性遮盖。
6.4.3.1 __delattr__(self, name)
6.4.3.2 __dir__(self)
把对象传给 dir 函数时被调用,列出属性。
6.4.3.3 __getattr__(self, name)
获取指定属性失败(搜索过实例,实例类和超类之后)之后被调用。
6.4.3.4 __getattribute__(self, name)
- 尝试获取属性时总会调用这个方法。(_寻找的属性是特殊属性或特殊方法除外_)
- 点号与 getattr 和 hasattr 内置函数会触发这个方法
- 调用__getattribute__方法且抛出 AttributeError 异常时,才会调用__getattr__方法
- __getattribute__方法的实现要使用
super().__getattribute__(obj, name)以 避免无限递归
6.4.3.5 __setattr__(self, name, value)
6.5 描述符(Descriptor)
- 描述符是实现了特定协议的类,协议包括__get__, __set__和__delete__方法
- 描述符的用法是:创建一个实例,作为另一个类的 类属性
- 通过类读取描述符实例(作为类属性),返回描述符实例本身(__get__方法返回描述符实例本身)
- 通过类修改描述符实例(作为类属性),直接修改类属性(__set方法 不会被调用 )
6.5.1 只实现__get__的描述符
- 若对象__dict__中无同名属性,通过对象实例读取同名描述符实例,返回描述符实例本身
- 若对象__dict__中存在同名属性,通过对象实例读取同名描述符实例,返回对象同名属性 (但特殊方法是特例,解释器 只在实例的类对象中 ,而不是实例对象的__dict__中查找特殊方法)
- 方法就是以这种类型的描述符实现的
6.5.2 只实现__set__的描述符
- 设置对象同名实例属性时,__set__方法插手接管
- 若对象__dict__中无同名属性,通过对象实例读取同名描述符实例,返回描述符实例本身
- 若对象__dict__中存在同名属性,通过对象实例读取同名描述符实例,返回对象同名属性
6.5.2.1 实现__get__和__set__的描述符
- 内置的 property 类就是这种类型 ,其__set__方法默认抛出 AttributeError 异常
6.6 元类
- 所有类都是 type 的实例,元类是 type 的子类,可以作为制造类的工厂
- 元类可以通过实现__init__方法定制实例
- 元类的__init__方法可以做到类装饰器能做的任何事情
- 如果想进一步定制类,可以在元类中实现__new__方法。通常情况下实现__init__方法就够了
6.6.1 使用 type 动态创建类
def fn(self, name='world'):
print('Hello, %s.' % name)
Hello = type('Hello', (object,), dict(hello=fn))
h = Hello()
print((type(Hello), type(h)))
(<class 'type'>, <class '__main__.Hello'>)
6.6.2 使用 metaclass 指定元类
类的默认元类是父类的元类 ,可以通过关键字 metaclass 指定元类:
class MetaFoo(type):
def __new__(metacls, name, bases, attrs):
print("metacls: {}, name: {}, bases: {}, attrs: {}".format(metacls, name, bases, attrs))
return type.__new__(metacls, name, bases, attrs)
def __init__(cls, name, bases, attrs): # name, bases, attrs: 与构建类时传给 type 的参数一样
print("cls: {}, name: {}, bases: {}, attrs: {}".format(cls, name, bases, attrs))
class Foo(str, metaclass=MetaFoo):
pass
print(dir(Foo))
metacls: <class '__main__.MetaFoo'>, name: Foo, bases: (<class 'str'>,), attrs: {'__module__': '__main__', '__qualname__': 'Foo'}
cls: <class '__main__.Foo'>, name: Foo, bases: (<class 'str'>,), attrs: {'__module__': '__main__', '__qualname__': 'Foo'}
['__add__', '__class__', '__contains__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__module__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
6.6.3 __prepare__方法
- type 构造方法及元类的__new__和__init__方法都会收到要计算的类的定义体,形式是名称到属性的映射,默认情况下,那个映射所使用的数据结构是字典
- Python3 引入了特殊方法__prepare__,这个特殊方法只在元类中有用,且必须声明为类方法,解释器调用元类的__new__方法前会先调用该方法
- __prepare__方法的第一个参数是元类,随后两个参数分别是要构建的类的名称和基类组成的元组,返回值必须是映射类型
- __prepare__返回的映射对象会传给__new__方法的最后一个参数,然后再传给__init__方法
6.6.4 与元编程相关的类属性/方法
6.6.4.1 cls.__bases__
类的基类元组。
6.6.4.2 cls.__qualname__
6.6.4.3 cls.__subclass__()
返回内存里现存的直接子类列表。
6.6.4.4 cls.mro()
解释器会调用这个方法获取超类元组。 元类可以覆盖这个方法以 定制要构建的类解析方法的顺序 。